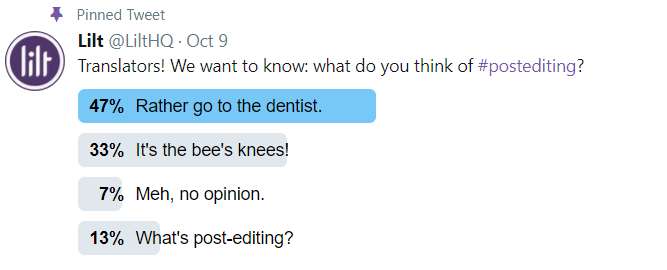
Beaucoup d'entre nous qui ont eu le déplaisir de faire de la post-édition sur une traduction créée par une machine conviendront que le processus est lent, fastidieux et passé de mode. Cependant, il y a toujours deux versions d'une histoire. Nous avons donc décidé de demander à nos abonnés de Twitter leur opinion sur le processus de post-édition. Les résultats ? 47 % des traducteurs préfèrent aller chez le dentiste plutôt que de faire de la post-édition.
Quel est votre rôle chez Lilt ? Je travaille dans la vente, le marketing et le succès client chez Lilt. Je suis incroyablement enthousiasmée par notre produit et de son potentiel, je suis donc ravie de travailler aux côtés de nos traducteurs et de partager notre technologie avec le monde.
Cette semaine, nous discutons avec un membre de l'équipe de Lilt, Marina Lee. Continuez à lire pour en savoir plus sur Marina et n'oubliez pas de lui dire bonjour lors de l'ATA 58 !
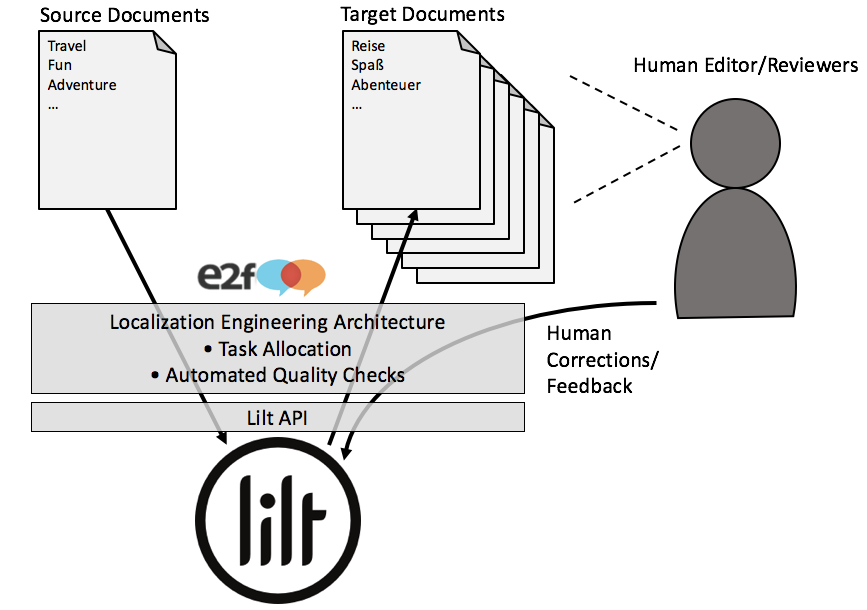
La combinaison de la traduction automatique (MT) avec l'apprentissage automatique (ML) adaptatif automatique permet un nouveau paradigme d'assistance automatique. De tels systèmes apprennent de l'expérience, de l'intelligence et des informations de leurs utilisateurs humains, améliorant la productivité en travaillant en partenariat, en faisant des suggestions et en améliorant la précision au fil du temps. Le résultat net est que les réviseurs humains produisent des volumes de contenu beaucoup plus élevés, avec presque le même niveau de qualité, pour une fraction du temps et du coût. L'assistance automatique peut économiser jusqu'à la moitié (ou plus) du prix des services de traduction humaine de haute qualité traditionnels. Ou, si vous êtes habitué(e) à la traduction automatique seule et que vous êtes mécontent(e) des résultats, regardez la qualité de votre traduction augmenter considérablement avec une augmentation marginale du prix.
Joyeuse fête des traducteurs, mes chers collègues traducteurs et interprètes ! En ce jour, je voudrais reconnaître et féliciter nos collègues traducteurs pour le travail que nous faisons et ce qu'il exige, et parler de la méconnaissance de tous les profanes qui supposent que n'importe quelle personne couramment bilingue peut aussi faire office de traducteur qualifié. Ce n'est pas le cas, c'est une chose tellement et (douloureusement) évidente pour nous, mais la confusion persiste. La traduction et l'interprétation sont des compétences très spécifiques qui, tout comme toute capacité spécialisée, nécessitent certaines facultés cognitives et opérationnelles. Certaines comprennent notamment une aptitude rapide à comprendre des sujets complexes et divers ; un esprit d'analyse et une capacité de recherche étendue : nous devons analyser des informations complexes, déduire les informations supplémentaires dont nous pouvons avoir besoin, et identifier les ressources, leur emplacement et la façon les trouver.
Notre nouvel éditeur de base de données terminologique avancé vous permet de gérer la terminologie plus efficacement en maintenant des termes organisés avec des méta-informations que vous pouvez personnaliser. Importez la terminologie avec des champs méta ou ajoutez vos propres champs. Vos termes apparaîtront à la fois dans le lexique et dans les suggestions de l'éditeur et vous aideront à améliorer la cohérence et la qualité.
Dans un monde où le piratage et les violations de données semblent faire la une plus souvent qu'à leur tour, une question courante se pose pour les traducteurs et les entreprises à propos de Lilt : mes données sont-elles sûres ? Pas besoin de vous inquiéter. Lilt a été construite avec cette préoccupation à l'esprit. Lisez ci-dessous les réponses à certaines questions courantes sur la sécurité dans Lilt. Mes données sont-elles partagées avec quiconque ? Les données de votre compte Lilt sont confidentielles. Elles ne sont jamais partagées avec d'autres comptes ou utilisateurs. Lorsque vous téléchargez une mémoire de traduction ou traduisez un document, ces traductions ne sont associées qu'à votre compte. Pour les clients commerciaux, les mémoires de traduction peuvent être partagées sur vos projets, mais elles ne sont pas partagées avec d'autres utilisateurs tiers.
Vous êtes-vous déjà demandé(e) ce qui se passe « sous le capot » pendant le processus de traduction et d'interprétation ? Examinons d'abord le mode d'interprétation. Les processus cognitifs qui ont lieu simultanément dans l'esprit et le cerveau d'un interprète sont intenses et le tout se passe presque simultanément. Les neurones tirent dans toutes les directions, enflamment différents circuits de traitement cognitif. Le cerveau est littéralement « en feu » comme le dit un scientifique cognitif russe. L'interprétation consécutive est différente de celle simultanée du point de vue de la science cognitive, dans le sens où les étapes de conversion du sens et de la reproduction sont retardées par rapport à la phase de réception et de déchiffrage du message. Cela ne facilite, cependant, pas le processus.
Un problème important dans le déploiement efficace de systèmes d'apprentissage automatique en pratique est l'adaptation de domaine, en raison d'un grand ensemble de données supervisées auxiliaires et d'un plus petit ensemble de données d'intérêt, en utilisant l'ensemble de données auxiliaires pour augmenter les performances sur le plus petit ensemble de données. Cet article examine le cas où nous avons des ensembles de données K de domaines distincts qui s'adaptent rapidement à un nouvel ensemble de données. Il apprend les modèles K distincts de chacun des ensembles de données K et traite chacun comme des experts. Puis selon un nouveau domaine donné, il crée un autre modèle pour ce domaine, mais en plus, il fait attention aux experts. Il calcule l'attention par le biais d'un produit à points qui calcule la similitude de la représentation cachée du nouveau domaine avec les représentations des autres domaines de K.