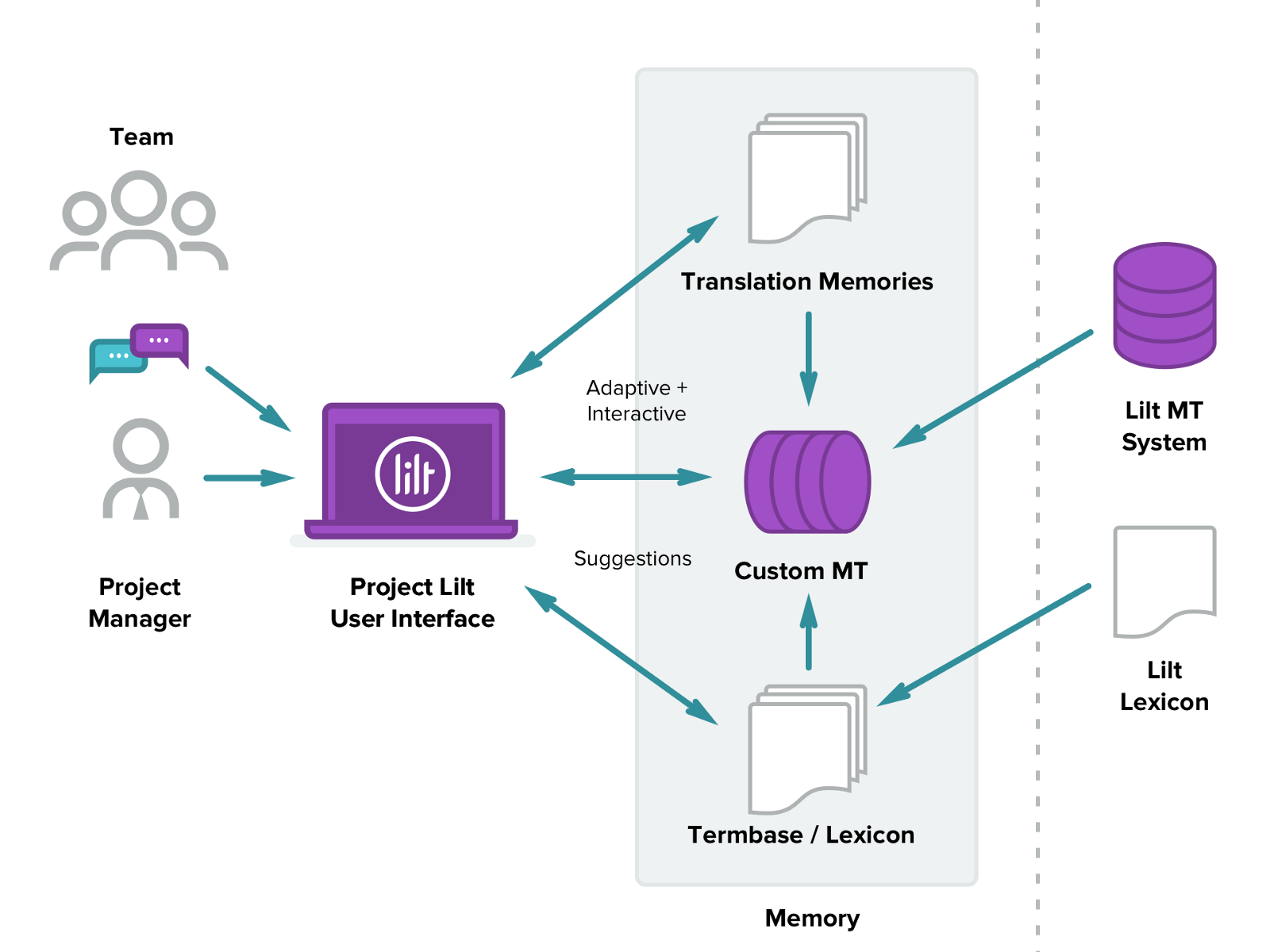
Lilt a été conçu pour maximiser la productivité de la traduction. Vous devez donc commencer à l'utiliser rapidement, plutôt que de passer du temps à apprendre à l'utiliser. L'interface et l'expérience utilisateur diffèrent des outils de TAO classiques. Le changement est difficile. Nous le savons. Mais nous avons conçu le système avec l'objectif de vous rendre productif en moins de 10 minutes. Les articles de notre base de connaissances vous transformeront en un utilisateur avancé, mais voici les bases de ce que vous devez savoir pour commencer…
Écrit par Kelly Messori L'idée que les robots prennent le contrôle du travail humain est loin d'être nouvelle. Au cours du siècle dernier, l'automatisation des tâches a tout fait : faciliter le travail d'un agriculteur avec les tracteurs ou remplacer le besoin de caissiers par des kiosques de libre-service. Plus récemment, à mesure que les machines deviennent plus intelligentes, la discussion est passée au sujet des robots qui prennent le contrôle de postes plus qualifiés, à savoir celui d'un traducteur. Une recherche simple sur le site de questions et réponses Quora révèle des dizaines d'enquêtes sur ce même problème. Tandis qu'une enquête récente montre que les experts de l'IA prédisent que les robots prendront le contrôle de la traduction des langues d'ici à 2024. Tout le monde veut savoir s'il sera remplacé par une machine et surtout quand cela arrivera.
Initialement publié sur LinkedIn par Greg Rosner. J'ai vu la phrase « travail d'agent d'ententien linguistique » dans ce livre blanc de Deloitte sur « Le gouvernement assisté par l'IA, en utilisant des technologies cognitives pour restructurer le travail du secteur public », utilisé pour décrire le travail de traduction assommant que beaucoup de traducteurs sont tenus de faire aujourd'hui par le biais de la post-édition de la traduction automatique. Et puis ce qui se passe vraiment m'a frappé. La triste réalité au cours des dernières années est que de nombreux linguistes professionnels, qui ont des décennies d'expérience particulière dans l'industrie, une expertise en traduction professionnelle et ont obtenu des diplômes en écriture créative, dont les emplois ont été réduits à un nettoyage de phrase par phrase de traductions qui découlent de Google Translate ou d'autres systèmes de traduction automatique (MT).
Lors de la recherche par faisceau en séquence pour les modèles de séquence, on découvre les mots suivants par ordre de probabilité. Cependant, lors du décodage, il peut y avoir d'autres contraintes ou des objectifs que nous souhaitons maximiser. Par exemple, la longueur de la séquence, le score BLEU ou les informations mutuelles entre les phrases cibles et sources. Afin de pouvoir accueillir ces desiderata supplémentaires, les auteurs ajoutent un terme Q supplémentaire à la probabilité de capturer le critère approprié et choisissent ensuite des mots en fonction de cet objectif combiné.
La façon la plus populaire de trouver une traduction pour une phrase source avec un modèle neuronal de séquence à séquence est une recherche de faisceau simple. La phrase cible est prédite un mot à la fois et après chaque prédiction, un nombre fixe de possibilités (généralement entre 4 et 10) est conservé pour une exploration plus approfondie. Cette stratégie peut être sous-optimale car ces décisions locales difficiles ne prennent pas le reste de la traduction en compte et ne peuvent pas être rétablies plus tard.
Les systèmes de traduction automatique neuronale génèrent des traductions un mot à la fois. Ils peuvent toujours générer des traductions fluides car ils choisissent chaque mot en fonction de tous les mots générés jusqu'à présent. Généralement, ces systèmes sont simplement formés pour générer le mot suivant correctement, en fonction de tous les mots précédents. Un problème systématique avec cette approche mot par mot de la formation et de la traduction est que les traductions sont souvent trop courtes et omettent le contenu important. Dans l'article Neural Machine Translation with Reconstruction, les auteurs décrivent une nouvelle façon intelligente de former et de traduire. Pendant la formation, leur système est encouragé non seulement à générer chaque mot suivant correctement mais également à générer correctement la phrase source d'origine en fonction de la traduction qui a été générée. De cette manière, le modèle est récompensé pour générer une traduction qui est suffisante pour décrire tout le contenu de la source d'origine.
Cet article décrit la technologie derrière les suggestions de traduction interactives de Lilt. Les détails ont été publiés pour la première fois dans un article de conférence universitaire, Models and Inference for Prefix-Constrained Machine Translation .(Les modèles et l'inférence de la traduction automatique déterminée par les préfixes) Les systèmes de traduction automatique peuvent traduire des phrases ou des documents entiers, mais ils peuvent également être utilisés pour terminer des traductions qui ont été commencées par une personne, une forme d'achèvement automatique au niveau de la phrase. Dans la littérature linguistique informatique, la prédiction du reste d'une phrase est appelée traduction automatique déterminée par les préfixes. Le préfixe d'une phrase est la partie écrite par un traducteur. Un suffixe est suggéré par la machine pour compléter la traduction. Ces suggestions sont proposées de manière interactive aux traducteurs après chaque mot qu'ils saisissent. Les traducteurs peuvent accepter la totalité ou une partie du suffixe proposé avec un seul clic sur le clavier, ce qui permet d'économiser du temps en automatisant les parties les plus prévisibles du processus de traduction.
Résumé : nous comparons les performances de la traduction humaine sur Lilt à SDL Trados, un outil de traduction assistée par ordinateur largement utilisé. Lilt génère des suggestions via un système de traduction automatique adaptatif, tandis que SDL Trados s'appuie principalement sur la mémoire de traduction. Cinq traducteurs internes anglais-français ont travaillé avec chaque outil pendant une heure. Les données de clients pour deux genres ont été traduites. Pour les données d'interface utilisateur, les sujets de Lilt ont traduit 21,9 % plus vite. Le débit de pointe dans Lilt était 39,5 % plus élevé que le taux de référence dans Trados. Ce sujet a également obtenu le débit le plus élevé dans l'expérience : 1367 mots source par heure. Pour un ensemble de données pour une chaîne d'hôtels, les sujets de Lilt étaient 13,6 % plus rapides en moyenne. La qualité de la traduction finale est comparable pour les deux outils.
Cet article est une annexe à notre article original publié le 10/01/2017 intitulé Évaluation de la qualité de la traduction automatique 2017. Conception expérimentale Nous évaluons tous les systèmes de traduction automatique en anglais-français et anglais-allemand. Nous rapportons le code BLEU-4 [2] insensible aux majuscules, qui est calculé par le script de score mteval, de la boîte d'outils open source Phrasal de l'Université de Stanford. La segmentation du texte en unités lexicales de NIST a été appliquée à la fois aux résultats du système et aux traductions de référence.