Al hacer una búsqueda de haz en modelos de secuencia a secuencia, se exploran las próximas palabras por orden de probabilidad. Sin embargo, durante la decodificación, puede haber otras limitaciones u objetivos que deseamos maximizar. Por ejemplo, la duración de la secuencia, la puntuación BLEU o la información mutua entre las oraciones de destino y de origen. Para dar lugar a estos deseos adicionales, los autores agregan un término Q adicional a la probabilidad que captura el criterio adecuado y luego selecciona palabras según este objetivo combinado.
Escrito por Kelly Messori La idea de que los robots se están quedando con los trabajos humanos no es para nada nueva. En el último siglo, la automatización de las tareas ha hecho de todo, desde facilitar el trabajo de un agricultor con los tractores hasta reemplazar la necesidad de cajeros con quioscos de autoservicio. A medida que las máquinas son más inteligentes, el debate ahora gira en torno a si los robots pueden hacerse cargo de trabajos más especializados, como el de un traductor. Una búsqueda sencilla en Quora, el sitio de preguntas y respuestas, muestra muchísimas preguntas sobre este tema. Mientras que un estudio reciente muestra que los expertos de IA predicen que en 2024 los robots se quedarán con la tarea de traducir idiomas. Todos quieren saber si los reemplazará una máquina y, principalmente, cuándo sucederá.
Los sistemas de TA neuronal generan traducciones de una palabra a la vez. Aun así, pueden generar traducciones fluidas porque eligen cada palabra basándose en todas las palabras generadas hasta ese momento. Por lo general, estos sistemas solo están entrenados para generar correctamente la próxima palabra basándose en todas las palabras anteriores. Un problema sistemático con este método de entrenamiento y traducción palabra por palabra es que las traducciones a menudo son demasiado cortas y omiten contenido importante. En el artículo Neural Machine Translation with Reconstruction, los autores describen una forma nueva e inteligente de entrenar y traducir. Durante el entrenamiento, se busca que el sistema no solo genere correctamente cada palabra próxima, sino que también genere correctamente la oración fuente original según la traducción que se generó. De esta manera, el modelo es recompensado por generar una traducción que sea suficiente para describir todo el contenido del texto fuente original.
La forma más popular de encontrar una traducción para una oración del texto de origen con un modelo de secuencia a secuencia neuronal es una búsqueda de haz sencilla. La oración de destino se predice una palabra a la vez y, después de cada predicción, se conserva una cantidad fija de posibilidades (normalmente entre 4 y 10) para seguir explorando. Esta estrategia puede ser insuficiente porque estas decisiones locales difíciles no tienen en cuenta el resto de la traducción y no pueden revertirse más adelante.
Este artículo describe la tecnología que está detrás de las sugerencias interactivas de traducción de Lilt. Los detalles se publicaron primero en un artículo de conferencia académica, Models and Inference for Prefix-Constrained Machine Translation (Modelos e inferencia para la traducción automática con prefijo limitado). Los sistemas de traducción automática pueden traducir oraciones enteras o documentos, pero también pueden usarse para terminar las traducciones empezadas por una persona, una forma de completar automáticamente a nivel de la oración. En la bibliografía lingüística computacional, la predicción del resto de una oración se llama traducción automática con prefijo limitado. El prefijo de una oración es la parte hecha por un traductor. La máquina sugiere un sufijo para completar la traducción. Estas sugerencias se proponen de forma interactiva a los traductores después de cada palabra que escriben. Los traductores pueden aceptar todo el sufijo propuesto o una parte de él con una sola tecla y ahorrar tiempo automatizando las partes más predecibles del proceso de traducción.
Resumen: comparamos el rendimiento de la traducción humana en Lilt con SDL Trados, una herramienta de traducción asistida por computadora ampliamente utilizada. Lilt genera sugerencias a través de un sistema de traducción automática adaptativa, mientras que SDL Trados depende principalmente de la memoria de traducción. Cinco traductores internos de inglés-francés trabajaron con ambas herramientas durante una hora. Se tradujeron los datos de clientes para dos géneros. En el caso de los datos de la interfaz de usuario, las personas que usaron Lilt tradujeron un 21,9 % más rápido. La producción superior en Lilt fue 39,5 % más alta que la tasa más alta en Trados. Esta persona también logró la producción más alta en el experimento: 1367 palabras del texto de origen por hora. En el caso del conjunto de datos de una cadena de hoteles, las personas que tradujeron con Lilt fueron 13,6 % más rápidas en promedio. La calidad de la traducción final es similar en las dos herramientas.
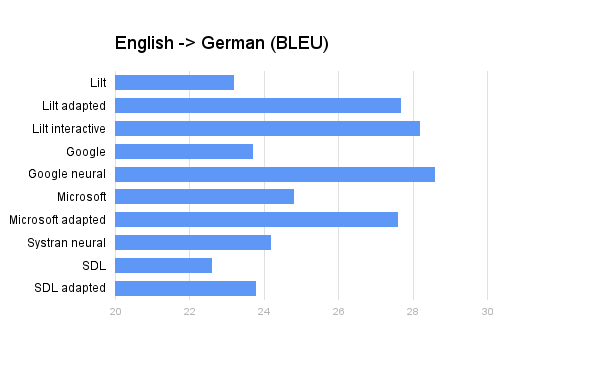
Este artículo es un anexo de nuestro artículo original publicado el 10/01/2017, titulado Evaluación de calidad de la traducción automática de 2017. Diseño experimental Evaluamos todos los sistemas de traducción automática para las combinaciones inglés-francés e inglés-alemán. Informamos de BLEU-4 [2], ignorando las diferencias entre mayúsculas y minúsculas, calculado por el script de puntuación mteval del conjunto de código abierto de la Universidad de Stanford, Phrasal. Se aplicó la tokenización NIST a las producciones de los sistemas y las traducciones de referencia.
El sector de los servicios lingüísticos ofrece una variedad de opciones de traducción automática demasiado amplia. Para ayudarte a distinguir qué es lo verdaderamente innovador de todas las opciones, tus compañeros de Lilt se proponen evaluar de forma reproducible e imparcial estas opciones con conjuntos de datos públicos y una metodología rigurosa. Con esto, queremos evaluar la traducción automática no solo en cuanto a la calidad de la traducción de referencia, sino también en cuanto a la calidad de los sistemas adaptados al dominio si están disponibles. La adaptación al dominio y las redes neuronales son los dos desarrollos recientes más emocionantes de la traducción automática disponible en el mercado. Evaluamos el impacto relativo de ambas tecnologías para los siguientes sistemas comerciales:
Publicación invitada de Jost Zetzsche, originalmente publicada en la edición de 16–12–268 de The Tool Box Journal. Algunos de ustedes saben que siempre me ha interesado la morfología. Déjenme decirlo de otra manera: he estado muy frustrado porque las herramientas de entornos de traducción que usamos no ofrecen morfología. Hay algunas excepciones, como SmartCat, Star Transit, Across y OmegaT, que ofrecen algunas herramientas morfológicas. Pero todos se limitan a una pequeña cantidad de idiomas, y cualquier esfuerzo para ampliarlos requeriría una codificación muy difícil y manual. Otras herramientas, como memoQ, han decidido que es mejor ofrecer coincidencias parciales que hacer reglas lingüísticas morfológicas específicas, pero eso, claramente, tampoco es la mejor respuesta posible. Entonces, ¿cuál es el problema? Además, en primer lugar, ¿qué es la morfología en las herramientas de entornos de traducción?






-1.jpeg)