
You may already know how machines translate between two human languages; if not, check out our introductory blog post on the subject. The following is an advanced exploration in one aspect of machine translation: format transfer.
Professional translation is more complex than just translating raw text. Translation must preserve formatting, such as bolding, italics, and markup to the best extent possible.
In this article, we describe how Lilt preserves formatting in translation. We’ll cover:
- Tag Representation
- Word Alignment and Attention
- Feature Visualization
- Fault Tolerance and Multiple Word Spans
Tag Representation
When localizing a document into another language, a translator must not only translate the text, but also transfer the formatting. Consider the following snippet from Wikipedia:

First paragraph of the Wikipedia article about translation
After translating the raw text content into, say, German, the translator still has to transfer the formatting (bolding, italicization, and HTML markup) into the target German text. Formatting can be represented as opening and closing tags that span a certain character range in the tags. Here’s how this looks in the Lilt interface:
In the beginning, the translator sees the segment in the source language including the formatting tags. The translator translates the segment by interacting with machine-generated suggestions. After finishing the translation, Lilt automatically transfers the formatting tags into the translator’s version. Ideally, the tags appear at reasonable positions in the translation; otherwise, the translator can manually change the tag positions via drag-and-drop or keyboard shortcuts.
Word Alignment and Attention
Reminder: source segments in machine translation are internally broken up into tokens, which are sub-word segments.
To transfer formatting we have to determine the positions of the formatting tags in the translation. To do this it’s useful to know which words in the source sentence and the translation correspond to each other - a problem called word alignment. We can later use this information to determine the positions of the formatting tags in the translation.
Neural networks for machine translation already contain a component called “attention” that models correspondences between tokens of the source sentence and the translation. Attention specifies how much each token of the original sentence influences the generation of a token of the translation as a probability distribution.
Attention is best visualized using a matrix with shading to indicate importance. Here’s an example of an German to English translation, with the tokens in German on the left, and those of the English translation on the top:
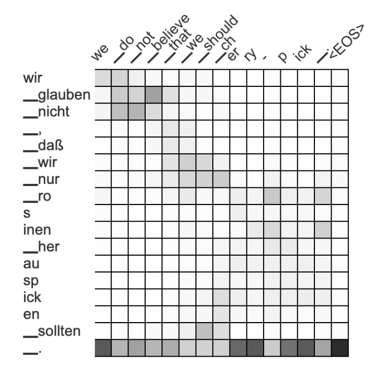
This is the average attention matrix extracted from a transformer-based MT system. The darker a spot in this matrix, the more important the token is in producing a certain token in the translation; that is: the higher the attention. For example, the most important tokens in generating English “_believe” are, in German, “_glauben,” “_nicht,” and “_.”
We can use this feature to transfer formatting, too. For example, if the word “glauben” were bold in the original text, we could use the attention matrix and select the darkest spot in the row, and bold the corresponding token in the translation. So we would bold the English word “believe.” Rinse and repeat for all tokens -- problem solved?
Not quite! Unfortunately, the attention matrix above is quite noisy. A lot of attention falls onto the punctuation token “_.”, which doesn’t reflect the importance a human translator would give the dot to produce the individual words of the English sentence.
The Transformer architecture we use to generate translations can be divided into an encoder and a decoder. The encoder encodes the source sentence into one vector per source token. The decoder iteratively generates one token of the translation. At each step the decoder uses its own state - another vector - to attend to the most relevant encoder tokens, combines the result with its own state and finally decodes the next token of the translation (Google’s original blog post contains a visualization of this process).
But sometimes it’s even possible to generate the next word of the translation without looking at the source sentence. To give an example, can you guess how the following sentence ends? “The Golden Gate Bridge is located in San …”
Even in these situations, we want to force the neural network to attend to the most relevant source representations. So we design a dedicated Alignment Layer to force the neural network to predict the next token, based only on a linear combination of the source representation. We use the decoder state to calculate the attention matrix that is used to determine the weights for the linear combination. Here’s the Alignment Layer in the context of the full transformer model:
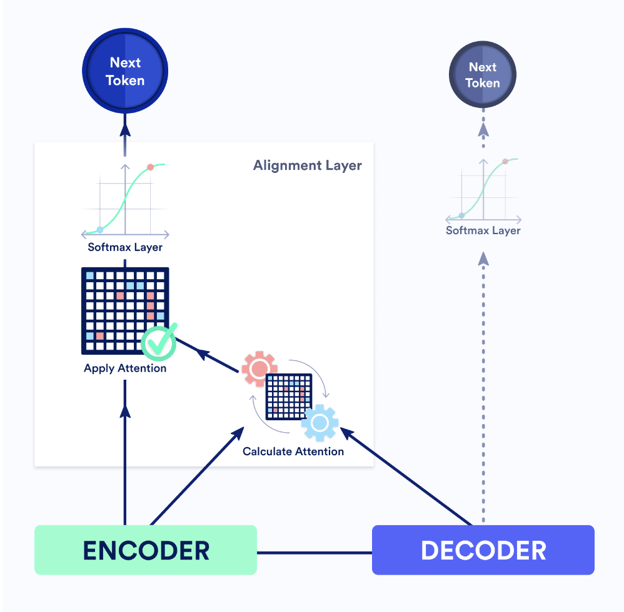
Instead of producing the next token based on the decoder state as the dotted line on the right would indicate, the Alignment Layer primarily uses the encoder states to predict the next token. This forces the attention of the Alignment Layer to focus on the most important source token. The resulting attention matrix now looks like this:
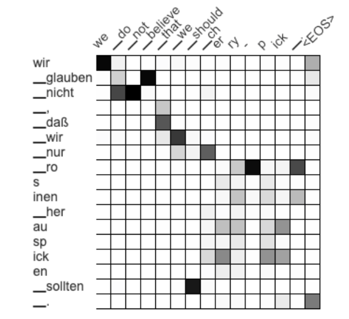
We’ve successfully gotten rid of high attention values to the punctuation mark in the translation! The remaining attention spots are now much darker, with less “slightly grey” boxes everywhere. Effectively, we’ve sharpened the attention of the model, which eventually leads to better tag projection and thus better format transfer.
Feature Visualization
While the Alignment Layer produces reasonable attention that we can use to transfer formatting, we can improve. For that, we will take a step back and recall how neural networks perform image recognition.
Neural networks for image recognition are trained to predict a label, for example the label “dog”, for a given image. In a trained image recognition model, one can analyze the feature a specific neuron represents by generating an input image such that that neuron activates strongly.
This generated image highly activates a neuron that seems to be important in recognizing dogs:

Optimized image towards maximizing the output of a neuron in an image recognition model. Source: distill.pub/2017/feature-visualization/
The image above is created by starting with a random input image, and optimizing it via gradient descent with an objective function to activate a single neuron in the network.
Back to our translation model: think of the previously-mentioned attention matrix as a grayscale image. Recall that each output token of the translation network corresponds to an individual neuron in the output layer of the neural network. Since we know the translation into which we will eventually transfer formatting tags, we can optimize the attention image towards a high activation of the output neurons corresponding to the desired translation.
In the video below we start with the original attention matrix and optimize it towards a high activation of the desired output neurons using a few steps of gradient descent:
This process also leads to an attention matrix which is more useful for formatting transfer.
Fault Tolerance and Multiple Word Spans
Until now, we’ve only considered how to transfer a tag pair around a single word. How would we handle multiple words? We’ll walk through a more complex example and present an algorithm to transfer formatting that can straighten out inconsistencies in the generated attention matrix.
Consider a tag pair spanning multiple words as in the following English to German translation:

To figure out how to transfer the formatting tags into the translation, we generate an attention matrix as usual, but only consider the highest scoring attention value for each target token:
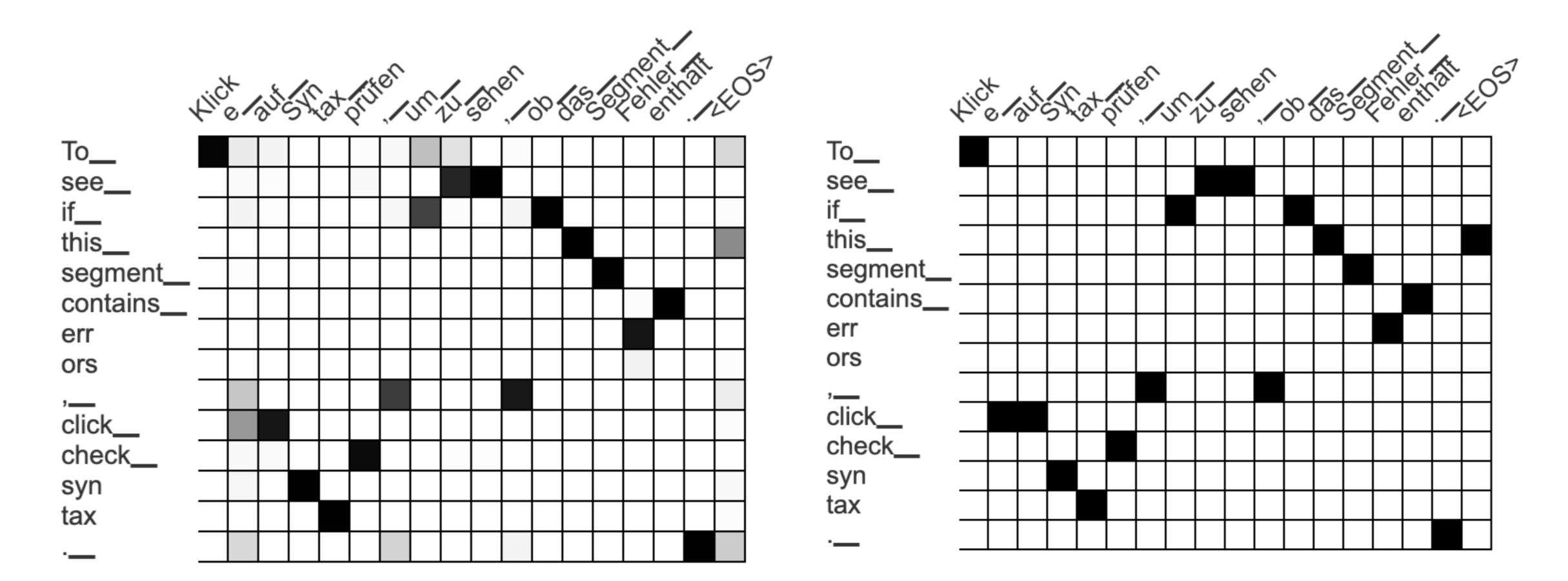
Automatically-generated attention matrices. The left matrix contains a probability distribution for each German output token, the right only retains the highest scoring attention score for each German token.
A simple way to transfer a tag pair covering a source phrase to a target phrase is the following:
- Look at all highest scoring attention values from the source phrase to target tokens
- Choose the left- and right-most target token in this set
- Span the tag pair around the left- and right-most target tokens
In this example we look at all attention scores for the phrase “To_ see_ if_ this_ segment_ contain_ err ors”, which are: “Klick”, “um_”, “zu_”, “sehen”, “ob_”, …, “Fehler_”, “enthält”. We select the left- and right-most of these tokens (“Klick” and “enthält”) and let the tag pair span all tokens in between:

This could be a reasonable approach if the attention matrix never contained any errors. But the attention matrix is automatically generated and often wrong! In our example, the incorrect entry between the tokens “To_” and “Klick” lead to an unreasonably long span for our tag pair.
At Lilt we developed an algorithm that is more fault tolerant. Instead of selecting the left- and right-most target word as the boundary for the tag pair span, we define a score for each possible span in the translation. This score is calculated by summing the following counts:
- Number of attention entries from the source tokens covered by the tag pair to tokens in the target span (in-span score)
- Number of attention entries from tokens not covered by the tag pair to tokens outside of the target span (out-of-span score)
We calculate this score for each possible span in the translation, and select the best-scoring span to transfer the tag pair. This approach assigns a low score to the unreasonably long target span in the previous example, because the “out-of-span score” is low. The highest-scoring span for our example is now “um zu sehen, ob das Segment Fehler enthält” with a score of 15:
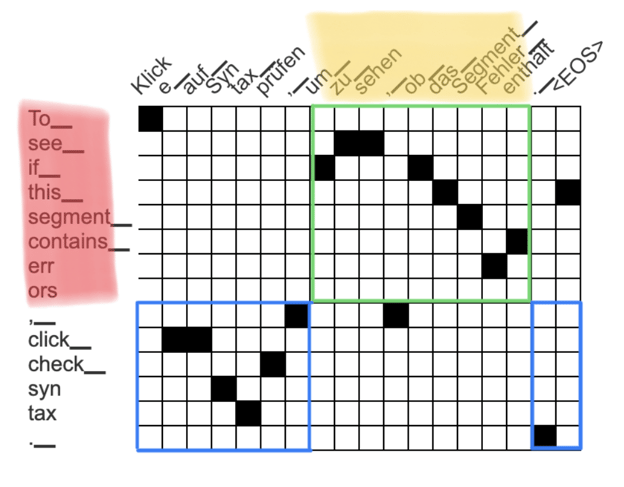
Above the fixed source span is highlighted in red and the span in the translation for which we calculate the score is highlighted in yellow. For the in-span score we count all black squares in the green area, which represents the attention between the two spans. For the out-of-span score we count the black squares in the two blue areas corresponding to the attention which is not associated with the source nor target span. Therefore, we get the score of 8 (in-span-score) + 7 (out-of-span-score) = 15.
The markup transfer algorithm found this optimal span by calculating the score of all possible target spans. This leads to the following, more reasonable result despite an imperfect attention matrix:

Further Reading
This blog post describes format transfer, but also highlights how techniques from a range of different areas can improve Lilt’s production system to better assist human translators. If you want to dive deeper into technical details of our systems, read some of our research:
- Adding Interpretable attention to Neural Translation Models improves word alignment: https://arxiv.org/abs/1901.11359
- End-to-End Neural Word Alignment Outperforms Giza++: https://aclanthology.org/2020.acl-main.146/
- Automatic Bilingual Markup Transfer: https://aclanthology.org/2021.findings-emnlp.299/
