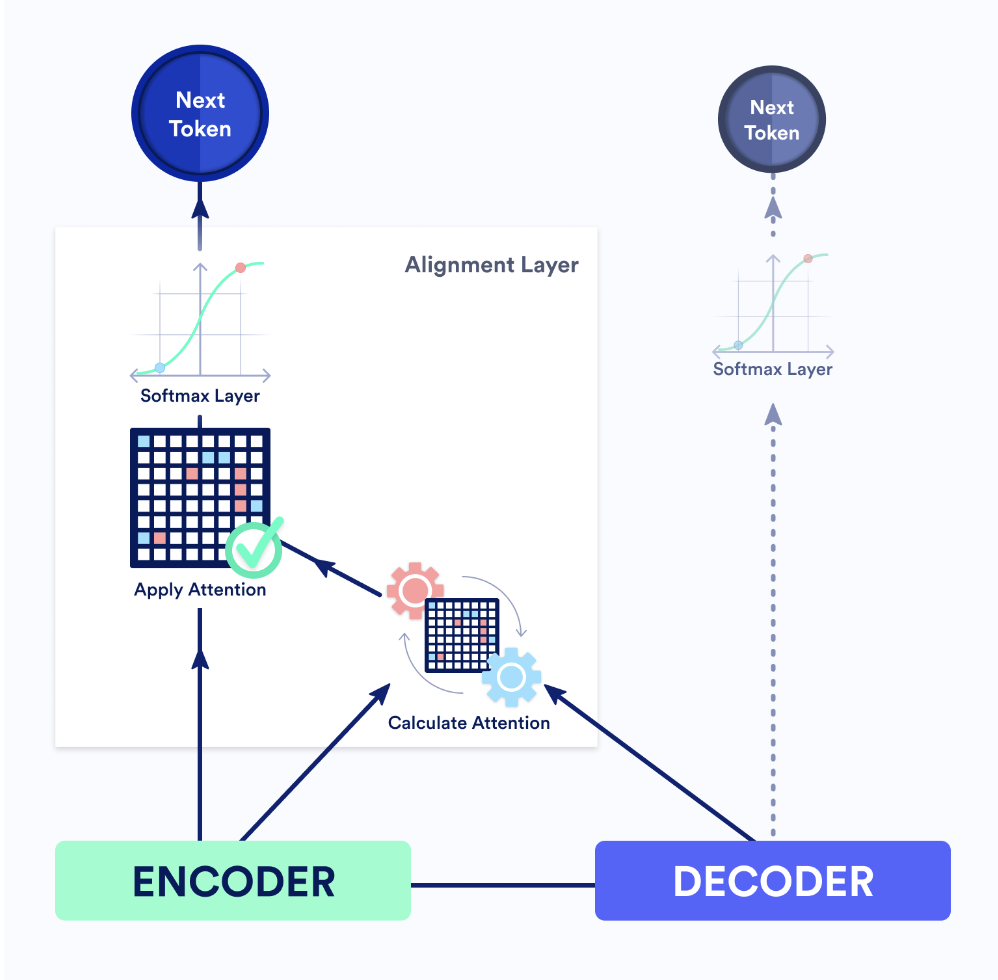
Here at Lilt, we have a team full of exceptionally smart and talented individuals that are working hard to solve the translation and localization industries’ toughest challenges. We’re always researching new ways to improve the day-to-day lives of localization leaders and translators alike.
That’s why we’re excited to share that Lilt’s own Thomas Zenkel, Joern Wuebker, and John DeNero have published a paper entitled “End-to-End Neural Word Alignment Outperforms GIZA++” in which they describe their purely neural word alignment system, which provides a 13.8% relative improvement in Alignment Error Rate. Here’s a quick recap of the paper and why it’s important for the machine translation community.
Using AI to translate text from a source language to a target language can be an extremely challenging task, given all of the contextual information required. While machine translation models the patterns to translate between source and target sentences, word alignment models the relationship between the words of the source sentence with a target sentence. In this paper, we compare our new, purely neural word alignment system to the current industry standard statistical system GIZA++.
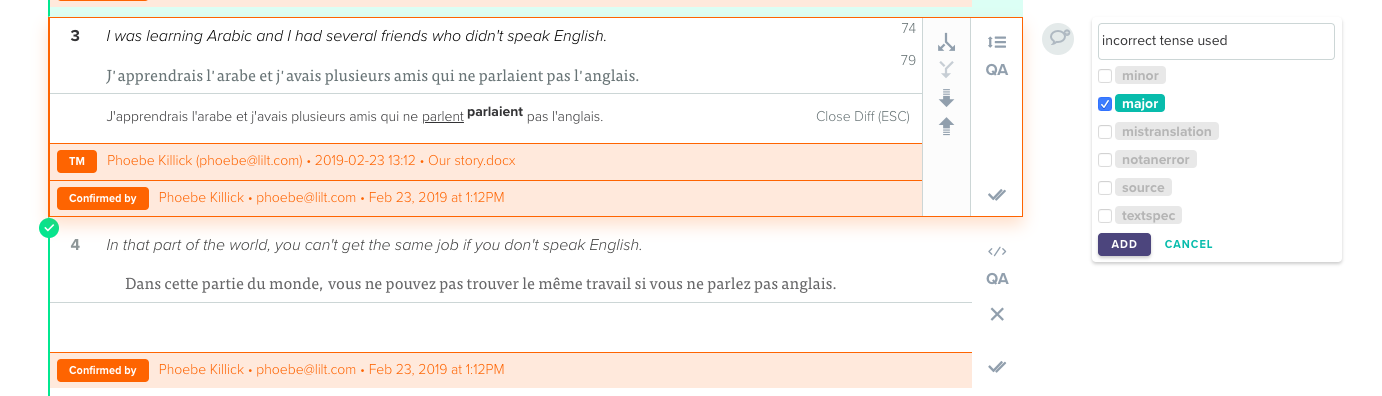
When translating digital content, linguists have to translate more than just the text on the page. Formatting, for example, is a commonly used and important aspect of online content that is typically managed with tags, such as <b> for bold and <i> for italics. When linguists work, they need to ensure these tags are placed accurately as part of the translation. Unfortunately, if the word alignment is inaccurate, it makes placing the formatting tags very difficult.
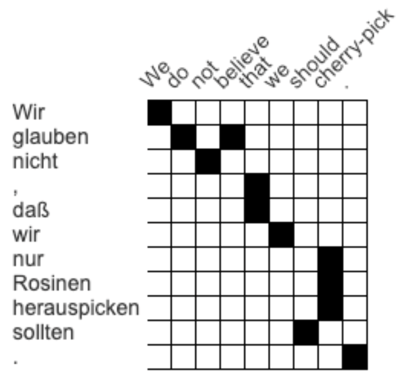
This image shows an attention matrix - it visualizes how the words of a source sentence and its translation correspond to each other. In the above example, wir in German matches to we in English, while nicht matches to not. This matrix was put together by a human translator, but for machine translation, this task can be much harder to do without any annotated training data.
For example, if the content requires that the above sentence in English - “We do not believe” - is bolded yet the word alignment is incorrect, the output in German will include formatted tags that are likely in the wrong position. That means that the incorrect text will be bolded and the linguist will need to go and manually change the tags.
The current state-of-the-art statistical word alignment system is called GIZA++, and it’s been the leader since 2000. These word alignment systems focus on Alignment Error Rate, commonly known as AER,which compares the alignment links of an automatic system to those produced by a human annotator.
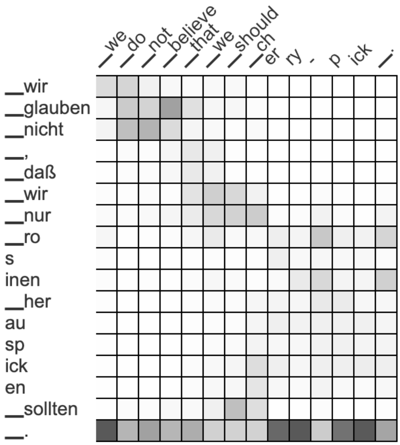
The Lilt team used a German > English data set to annotate their approach. Using that data, GIZA++ had an AER of 18.9%. To see how they could improve on that score, Zenkel and team used the most commonly used machine translation system (a transformer) and visualized its attention activations. Extracting alignments based on these yields a high AER of 66.5%. However, instead of only showing black and white alignments, the matrix above now uses a grey scale - more black means more correspondence between words, more white means less correspondence.
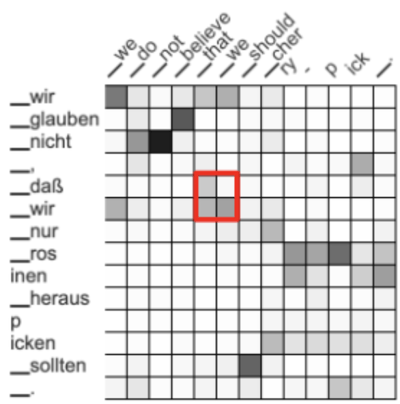
However, by adding in new steps that focus on word alignment quality instead of translation quality, they were able to reduce the AER to 34.5%. They then built systems that reward relationships between neighboring words. For example, the neighboring words dass wir and that we correspond to each other. While a grey pattern has emerged, the team wanted to increase the attention in the highlighted area above.

The result? A more concentrated attention matrix, one that more accurately predicts the relationships between words. That step reduced the AER down to 27.8% - closer to that of GIZA++.
Perhaps the biggest change, however, came when the team started to think beyond just translating from German to English. If you compare the German to English model (forward model) to the English to German model (backward model), the alignments should be very similar - if not identical.
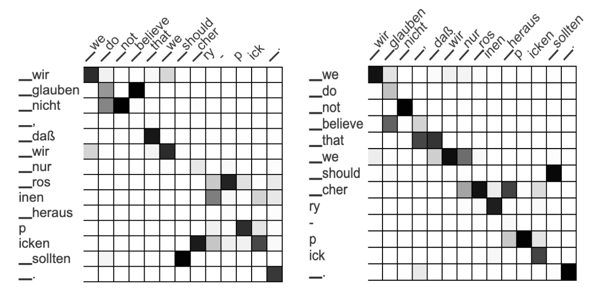
By forcing the system to use the same word alignment (or attention matrix) for both the forward and backward models, it can better understand and predict the relationships between words. Remarkably, this dropped the AER to 17.9%, dipping below the impressive GIZA++ score of 18.9%. With one more tweak, the team was able to improve the Alignment Error Rate to 16.3%, showing just how successful the word alignments were.
Ultimately, the team’s contributions to word alignment approaches have outperformed even the most widely adopted, state-of-the-art system available. Tests in other languages (English-French and Romanian-French) have confirmed that this approach outperforms competitive statistical alignment systems, resulting in a lower AER than its previous models. Improved word alignments increase the quality for automatically transferring formatting information into the translation.
We’re extremely proud of the amazing work that Zenkel, Wuebker, and DeNero have accomplished, and we’re excited to see what the experts on the Lilt team are able to come up with next.