
We’re pleased to announce a new feature in our interface that improves the translation review process. Previously, reviewers could make general text comments about errors and introduce categories by using hashtags to indicate the type of error (such as #punctuation or #mistranslation). However, it was still a manual process to collect the different hashtags and identify precisely where the error occurred.
Now, when reviewers find an error in a translation, they can categorize the type of error made - allowing them the ability to provide more detailed feedback. With the new experience, reviewers can select the kind of error (or errors) from a checklist of commonly made mistakes.
The various error types are now fields within the revision report document. The reviewer can also now see exact error placement along with the specific error type, providing a birds-eye view over the kinds of errors that occur most frequently in their projects. From here, translation managers can adjust their text specifications, and experience even greater efficiency gains.
We love making workflow improvements such as this one, and the structure it provides in feedback loops.
Reviewers will now see a set of checkboxes to indicate the type of error found, and will still have the option to leave plain text comments as well. Here’s the new experience:
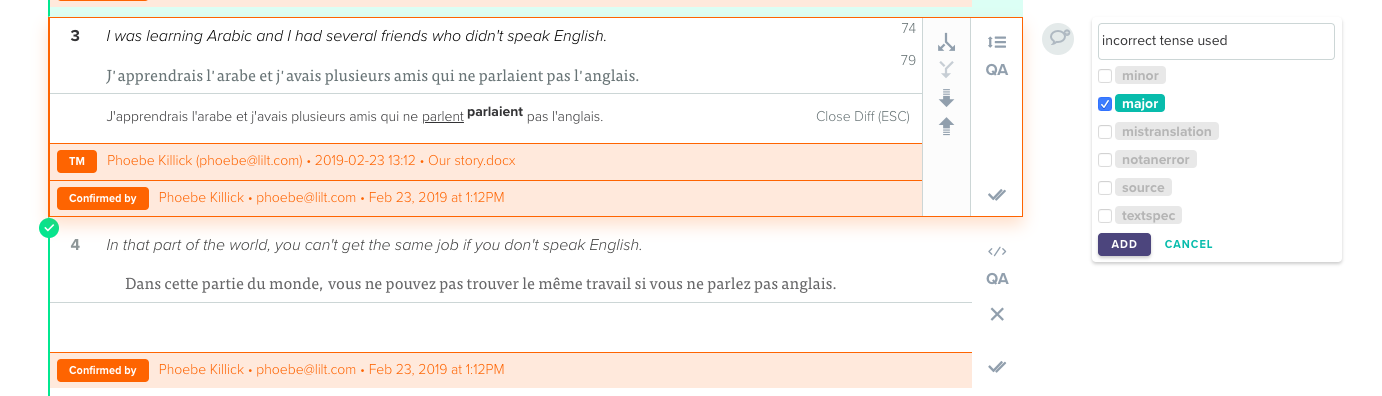
"The addition of translation review categories makes it much easier to see trends in the type of errors," said Translation Manager Phoebe Killick. "Previously, I had to manually look through the delivery revision report to find trends in the types of errors. Now, I can immediately aggregate and filter by types of errors to find individual translators who are consistently making the same errors, or update the instructions for all translators where there are frequent similar errors across the board."
We’d love your feedback on the new experience. Let us know your thoughts @LiltHQ on Twitter.
Localization is profitable. You can measure it.
Having a hard time tying localization to ROI? We've got you. The Ultimate Guide to Measuring Localization ROI covers everything you need to know to tie your market expansion efforts to business goals and revenue.



