Over the last few decades, modern machine translation has improved more and more. From its beginnings in the 1940s to its contemporary improvements, machine translation has undergone plenty of change. As it’s improved, however, questions about its ability have been raised time and time again.
In our recent webinar, The Future of Machine Translation, Lilt's CEO Spence Green spoke about the background of machine translation, the state of the art today, and what new developments and improvements we can expect in the future.
The future of MT is not as cut and dry as it may seem, and the importance of human involvement is crucial. At Lilt, we know just how important translators are, and we’ve built our ecosystem to provide them with the tools they need to be more efficient than ever. After all, there’s a reason why over 70% of translators prefer to work with a system that augments their abilities instead of simply editing translated content.
Spence first took a step back to better understand the history of machine translation and how we’ve gotten where we are now. MT research started in the 1940s, though it wasn’t what you might think. Early on, research focused on writing linguistic rules on how to translate from one language to another. While the results proved to be relatively accurate (depending on linguistic representation), there are too many sentences in the world for that manual process to be feasible.
The 1980s brought more computational power, and IBM started building systems that could learn rules from bilingual data inputs. The next of MT was phrase-based systems - instead of word to word translations, it was chunks of text to chunks of text. These days, we’re onto neural networks that can take many more parameters to translate data.
The raw MT quality has gotten much better over the years. But for businesses, raw output doesn’t guarantee quality. Google Translate, for example, is fast and inexpensive, but has a lower quality output. It’s commonly used in situations where speed and cost are the primary considerations over quality - for example, with a business that has to translate enormous and ever-growing quantities of user-generated content. Airbnb users don’t expect translations to be perfect on a post for a listing. Often, the source text isn’t perfect to begin with, so raw MT output from systems like Google Translate can be acceptable.
 The Machine Translation plus Post-Editing workflow: content gets translated then edited by a linguist.
The Machine Translation plus Post-Editing workflow: content gets translated then edited by a linguist.
But it’s still less functional for more professional content, like financial documentation, product information, law, etc. MT plus Post-Editing (MTPE) adds a human review step after the MT system runs its translations. While that may be relatively inexpensive, it’s a much slower process than raw MT output and quality can still suffer. On top of that, MTPE is a process that translators strongly dislike, as they report finding the work unfulfilling.
Research on the topic supports that claim. In a study done by CSA Research, 89% of translators said they prefer to translate text instead of editing raw MT output. And while the quality of MTPE translations is usable, it often sounds more literal, since the base translation is still created by a machine. And since humans edit the raw output, there are no MT efficiency gains that benefit translators, as the MT models don't improve over time with the translator's input - only when the models are manually retrained.
So if not MTPE, what’s the future of machine translation? At Lilt, we firmly believe that AI will augment, not replace, human translators. While machines are great at automating repetitive tasks, they don’t deal with complex tasks nearly as well. Complex tasks that involve reasoning, context, and integrating information from many different sources of knowledge is where humans excel - and where the gap between human ingenuity and machine ability is most clear.
The focus has already started and will continue to shift towards “human-in-the-loop” AI, a system where the human-to-machine feedback loop helps to improve the output over time. There are already plenty of examples of human-in-the-loop AI systems in the world currently, from automotive to aerospace to medical.
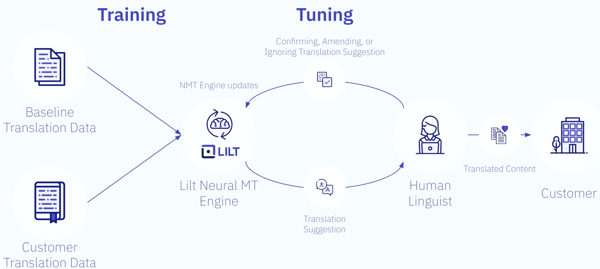 Lilt's adaptive machine translation features human feedback to train and update systems.
Lilt's adaptive machine translation features human feedback to train and update systems.
This figure shows the system for translation. The model is first trained with baseline and customer translation data. Once the engine provides translation suggestions, the human linguist can review and provide immediate feedback. That feedback then updates the engine for future translation suggestions, and so on.
The result? Future answers are more accurate based on a constantly updated model, providing efficiency improvements for translators when it comes to both quality and speed. According to the same CSA Research study, 71% of linguists prefer working with an adaptive MT system like Lilt as opposed to editing raw MT output.
If you want to learn more about the future of machine translation, translation services, and how human-in-the-loop AI is already making an impact on systems around the world, watch the on-demand webinar here. Get more of Spence’s insights and understand how you can set your company up for the future with the right adaptive MT solution.