Today we’re excited to announce the Lilt Contextual AI Engine, a new generative language model that implements in-context learning (ICL). With 5x more parameters than the previous Lilt model it replaces, Contextual AI powers the Verified (with human verification) and Instant (fully automatic) enterprise localization workflows. Contextual AI outperforms both GPT-4 and Google Translate while remaining over 1000x more compact than GPT-4, meaning that self-managed customers of the Lilt AI Platform can deploy on their own compute.
The Contextual AI Engine supports the two key features for accelerating localization workflows: ICL and real-time prompt completion. First, ICL eliminates the need for manual retraining cycles. Feedback from human linguists, who verify the accuracy and factuality of translation, is incorporated into the model in real-time. Second, the new models complete, in real-time, prompts from those human linguists. These models are deployed on globally distributed infrastructure, enabling fast ICL and prompt completion in all regions.
The system architecture is a generative pre-trained transformer [1] model designed specifically for translation with both an encoder network for understanding the source and a decoder network to generate completions. ICL is implemented via fine-tuning adapter layers [2] within the network immediately after a linguist completes a sentence, such that the model ingests knowledge from all user-provided data. This differs from GPT-4’s approach to learning from user data (few-shot learning), which is restricted to learning from typically fewer than ten examples. We extended this state-of-the-art ICL approach with localization-specific functionality such as automatic bilingual markup transfer [3] and automatic correction of human translation [4].
Contextual AI maintains separate contextualized models for each customer and content type (e.g., legal, product descriptions, creative marketing, etc.) that are immediately deployed via a multi-stage caching architecture. It also handles enterprise language content requirements, such as preserving capitalization and markup tags, adhering to terminology and DNT (do-not-translate) constraints, and seamlessly connecting to dozens of content platforms.
Another new feature of this generation of models is that they incorporate terminology constraints in a way that is sensitive to both context and linguistic concerns, so that terms are correctly inflected and formatted and the text surrounding the term is adapted for fluency and accuracy. This approach is similar to how a professional linguist uses terminology: incorporating all of the relevant context in each text generation decision.
Contextual AI already exhibits breakthrough results in real-world workflows. For example, across all Lilt English-to-German customer workflows, the word prediction accuracy (WPA) [5], i.e. the number of words that are correctly predicted by AI and therefore do not need to be typed by a human, improved from 77.4% to 85.0% after we deployed the new model. That is, linguists need to type only 3 out of every 20 words on average, while the rest is generated automatically by Contextual AI.
In addition, the new generation of translation models show improved quality especially with respect to long-distance dependencies, fluency and adjusting to user input, as is highlighted in the following examples.
Long-distance dependency / fluency example
V1:

V2:

Fluency example
V1:
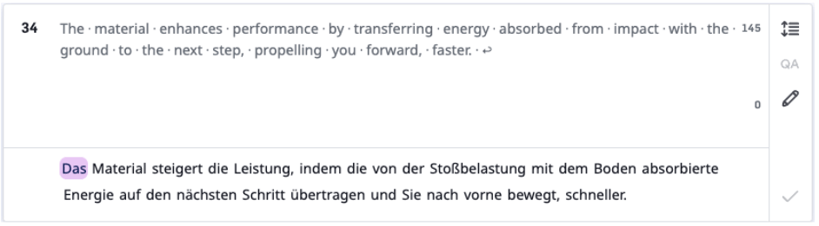
V2:

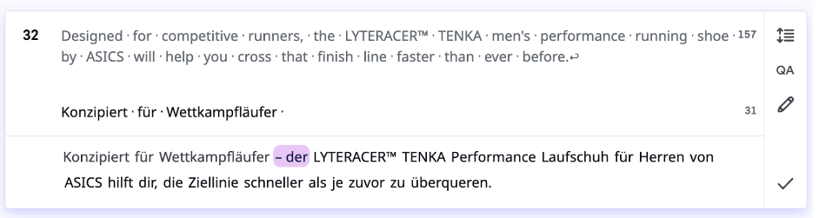
Example for adjusting to user input
V1:
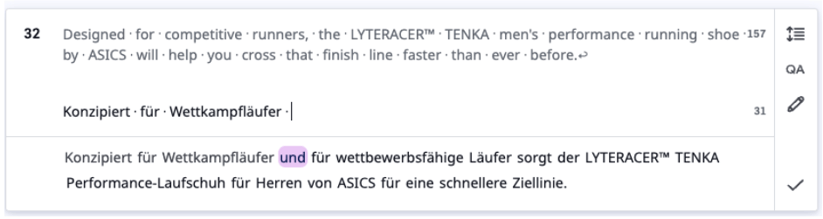
V2:
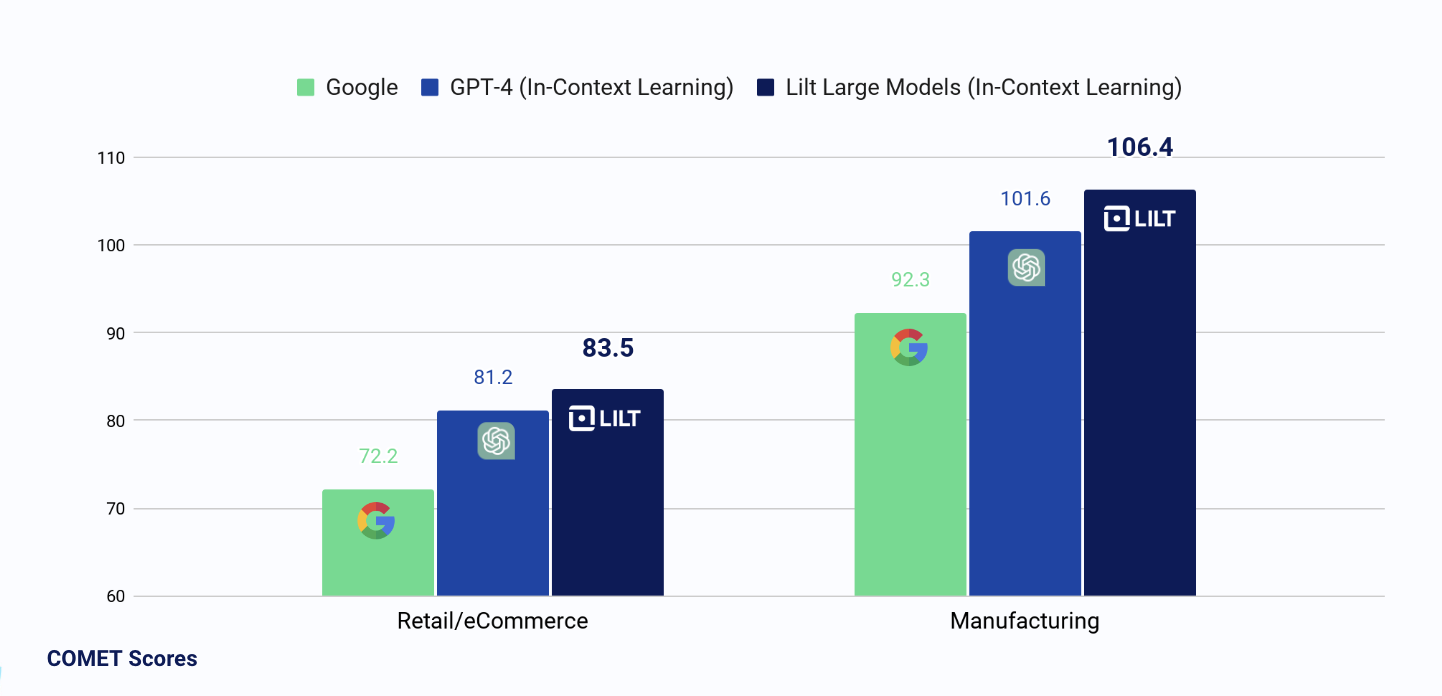
We also compared Contextual AI to Google Translate and GPT-4 on the ACED Corpus [6].** We report both BLEU and COMET scores on actual enterprise localization data [7]. Google and GPT-4 were queried through their respective APIs. For GPT-4, we implemented ICL as fuzzy 5-shot prompting. To achieve this the team built a custom prompt generator based on the sentence transformers library [8].
** NOTE: The ACED corpus consists of public web data dating to 2020. As GPT-4’s training set includes web data through 2021, the GPT-4 scores may be inflated.
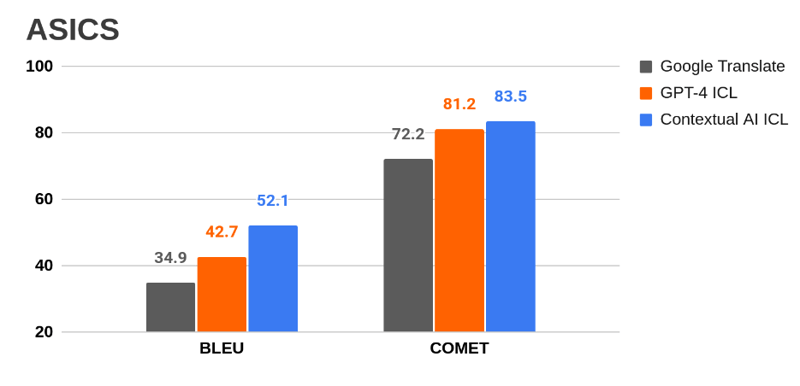
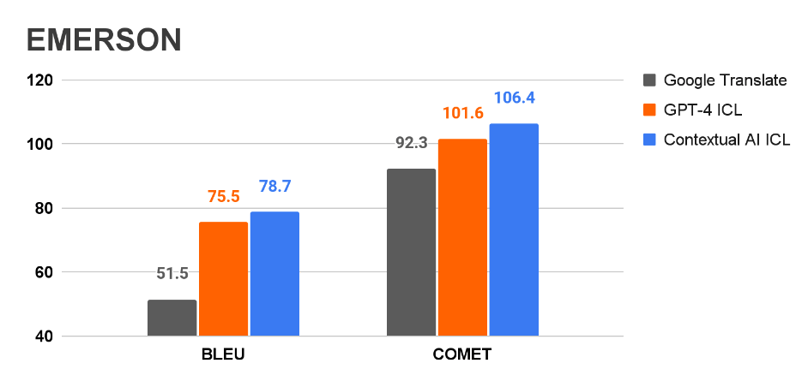
For GPT-4, ICL improves performance significantly. Contextual AI ICL achieves the best results for both test sets.
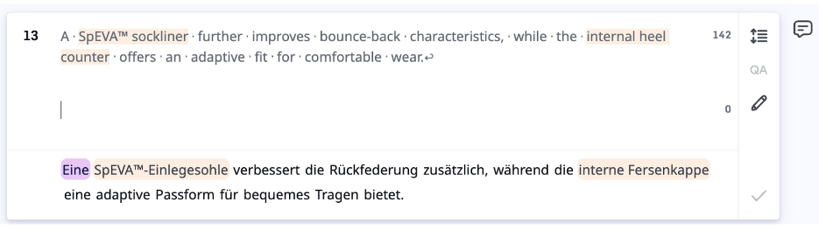
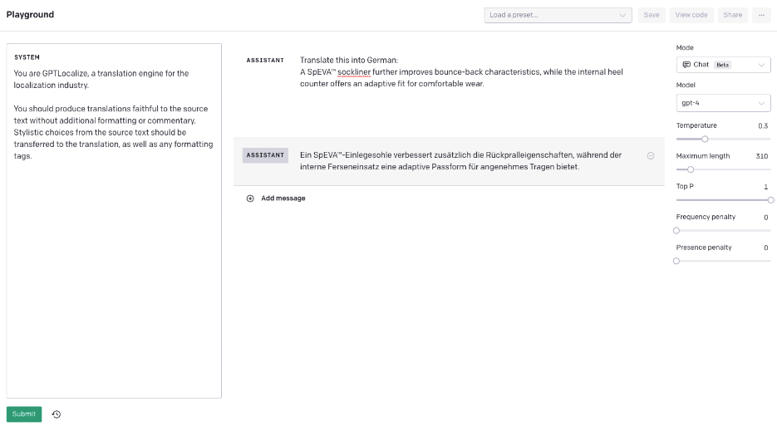
Here is an example sentence, comparing GPT-4 with Contextual AI. GPT-4 misses gender agreement for the article before “SpEVA™-Einlegesohle” (“Ein” vs “eine”). Contextual AI correctly uses the term for “internal heel counter.” The translation of “bounce-back” also sounds more natural in German.
Lilt Contextual AI produces state of the art results for verified enterprise localization use cases. We’re excited for everyone to try this new system and send their feedback.
.jpg?width=1356&height=207&name=Lilt-Blog%20CTA%20(1).jpg)
References
[1] https://arxiv.org/abs/1706.03762
[2] https://arxiv.org/abs/1909.08478
[3] https://aclanthology.org/2021.findings-emnlp.299
[4] https://aclanthology.org/2022.naacl-main.36/
[5] https://aclanthology.org/2016.amta-researchers.9.pdf
[6] https://aclanthology.org/2022.naacl-main.36/