
In written content, tags provide important formatting information, such as turning text into a hyperlink or making text bold. Lilt’s translation editor supports tags to save translators the manual effort of adding add tags back into a translation.
A translation editor needs the following three features:
- Tag parsing: Automatically parse user uploaded content to extract tags.
- Tag projection: Project tags from the source content to the target content after translation. Lilt does this via machine learning -- see our blog post on Format Transfer for more details.
- Tag editing: Allow linguists to modify tag placement in the target content. Note that linguists should never be able to create or delete tags. If a linguist selects and deletes text containing tags, the tags should be moved.
In this blog post, we’ll explore the efforts of our engineering team to improve our tag editing functionality and the challenges we’ve faced along the way.
The Lilt CAT Editor, Then
We’ll start our journey with the second version of Lilt’s Computer-Aided Translation (CAT) editor, internally known as CATv2. CATv2 existed in Lilt from September 2017 to May 2021. was built in Angular 1.5 using Quill, a rich text editor framework. However, Quill didn’t support tags, so we built a distinct tag editing mode that was separate from the Quill text editor system.
In this mode-based system, after users added text in text editing mode, tags were invisibly projected from the source text into the target text. Linguists who wanted to view and edit tags would switch modes:
- Text mode only displayed text, and allowed linguists to add/edit target text for a segment.
- Tags mode displayed both text and tags, but only allowed linguists to edit tags.
Here is a screenshot of the original version of Lilt (with dummy German text -- ist ja keine richtige Übersetzung!), where you can see the “Tags” mode at the bottom that had to be switched to:
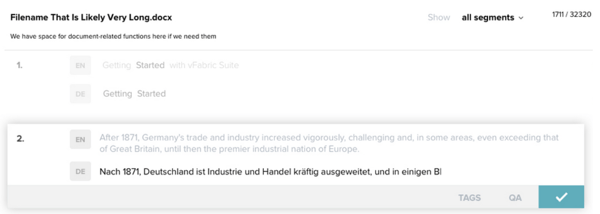
This system was clunky, but better than no tags!
Towards the end of 2019, a tag editor overhaul became crucial. The mode-based system was painful for linguists and production managers, who are responsible for delivering final translations to customers. Modifying text in text mode did not update the relative position of tags, and there was no way to see where the tags were without switching into tags mode. So, editing text after manipulating tags would often result in misplaced tags.
Further, changing tags in accepted segments took many clicks. Users first had to un-accept the segment, switch the segment to tags mode, move the desired tags, and then reaccept the segment. Production managers had to repeat this multiple times when running tag quality assurance.
The solution was to allow users to simultaneously edit text and tags in the editor, requiring a complete rework of CATv2. Make way for CATv3!
Strategy for Improvement
Proudly Found Elsewhere
We first thought of rebuilding the entire editor from scratch, thinking our needs to be highly specialized, and perhaps suffering from a bit of “not invented here” syndrome. But, we soon realized that text editors are complex beasts, and we were reinventing the wheel. So, we decided to stop initial development work and reinvestigate existing solutions.
We chanced upon Slate, a customizable framework for creating rich text editors. Slate did not come with built-in support for tags, but it would allow us to build a custom tag editor system on top of it. Although it seemed to be in permanent beta and suffered from stale documentation, it was the most viable option for implementing a simultaneous text and tags editor.
We stumbled at first, encountering long standing PRs like fixing a bug with cursor movement in right-to-left elements, but eventually overcame these hurdles.
Syncing Tag Data
Lilt’s editor autosaves, meaning whenever a user makes a change in the HTML editor, those changes are automatically synced within the editor and the backing database. Syncing is a challenge given our custom tag system on top of a text editor not designed to handle them.
Specifically, we ran into the following issues in our previous implementation:
- Our tags in HTML lacked IDs, meaning they could not be uniquely referenced. Thus, the editor sometimes could not determine which tag had moved, if more than one tag had occupied the same position.
- We did not keep track of relative tag order, only the character position within the string. If multiple tags occupied the same position, there wasn’t a reliable way to determine the correct order of those tags.
The Lilt CAT Editor, Now
With the challenge in front of us, we set off to build our new text and tags system on top of Slate. We wrote the simultaneous text/tag system in React, although the rest of the surrounding editor, CATv2, remained Angular 1.5.
Further, we used React DnD to create the drag and drop functionality for tags. And, we modified the editor to allow tags to be given unique IDs in HTML to refer to them consistently, ensuring proper syncing.
Once everything was all put together, we ended up with a simultaneous text and tags editor that fell somewhere between a simple text editor and a WYSIWYG editor. Tags are now visibly projected when a segment is confirmed, and users could view and move tags directly in the editing area:
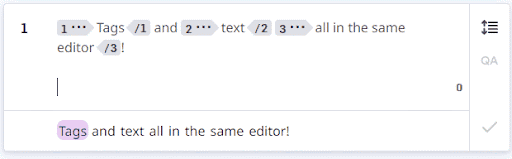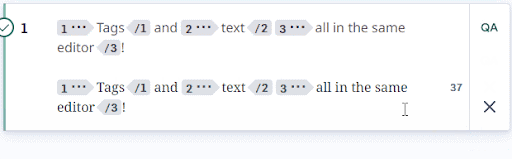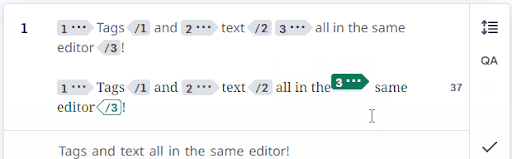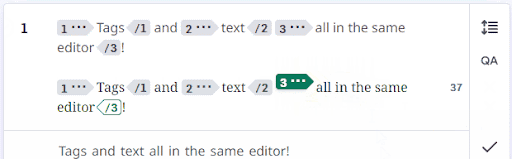
When we launched, we ran into many issues syncing the HTML display, editor system, and internal representation. The CATv2 Angular codebase was reaching its limit with both the tag system and the various business rules surrounding editing, confirming, and accepting segments. Adding new functionality or making changes was dangerous, as the code was tightly coupled, beginning to age, and dense. Thus, after reworking the text/tags editor in React, we started rewriting the entire editor system in React + Typescript, using modern coding conventions.
We rolled out CATv3 as an optional beta to customers, allowing a fallback to CATv2 to retain productivity. For a few months, we maintained both CATv2 and CATv3. We finally pulled the trigger to set CATv3 as generally available in May 2021, and tags became a lot simpler to manage. Users rejoiced!
Tag Data Structure
Current Structure
Here is an example JSON structure of our tags, which typically come in pairs. Tags are uniquely identified with id, their absolute positions are given by the key position, and nested references are indicated via the parent key. solos are tags that do not have a pair, for example a <span /> or <br /> tag in HTML. nts refer to non-translatables, which are usually placeholders in the translated text that should not be translated, but are also represented as tag-like structures.
{
"pairs": [
{
"open": {
"tag": "g id=\"1\" ctype=\"link\" equiv-text=\"[#$dp3]\"",
"position": 47,
"origin": "xliff"
},
"close": {
"tag": "/g",
"position": 68,
"origin": "xliff"
},
"parent": -1,
"id": 1
},
...
],
"solos": [],
"nts": []
}
Future Structure
The future JSON structure of our tags will be a one-dimensional array per segment, where each array represents all the tags in one text segment. The previous format can cause ambiguity in tag/nt positions if they are overlapping. The 1D array approach is a reduction in complexity as it would allow us to pass the data structure through various layers of our system (starting from the database) without transformation.
An example follows:
[
{
"id":"1",
"type":"openingTag",
"position":4,
"name":"strong",
"style":...,
"properties":{
"id":"1",
"ctype":"x-strong",
"equiv-text":"strong"
}
},
{
"id":"1",
"type":"closingTag",
"position":20,
"name":"strong",
"style":{
},
"properties": ...
},
...
]
What’s Next
Our future improvements include continuing to work on resolving corner cases with tag de-syncing, and reconfiguring the internal representation of tags to be a 1D array. Our tags solution has at times been programmatically crude, but functional. Keeping our linguists happy with a text editor -- a core part of their workflow -- while maintaining overlapping implementations is a hard challenge. One we gladly tackle for our customers!


