Happy Translator’s Day, my fellow Translators and Interpreters! On this day, I would like to recognize and commend fellow translators for the work we do and what it requires, and address any layperson’s misconception that a fluent bilingual may as well serve as a qualified translator. That this is not so may be so (painfully) obvious to us, but the confusion persists. Translation and interpretation are very specific skills which, just like any specialized capability, requires certain cognitive and operational faculties. Some of these are: a quick aptitude for understanding complex and diverse subjects; an analytical mind, and extensive research ability — one has to analyze complex information, deduce what additional information they may need, and identify the resources of where and how to find it.
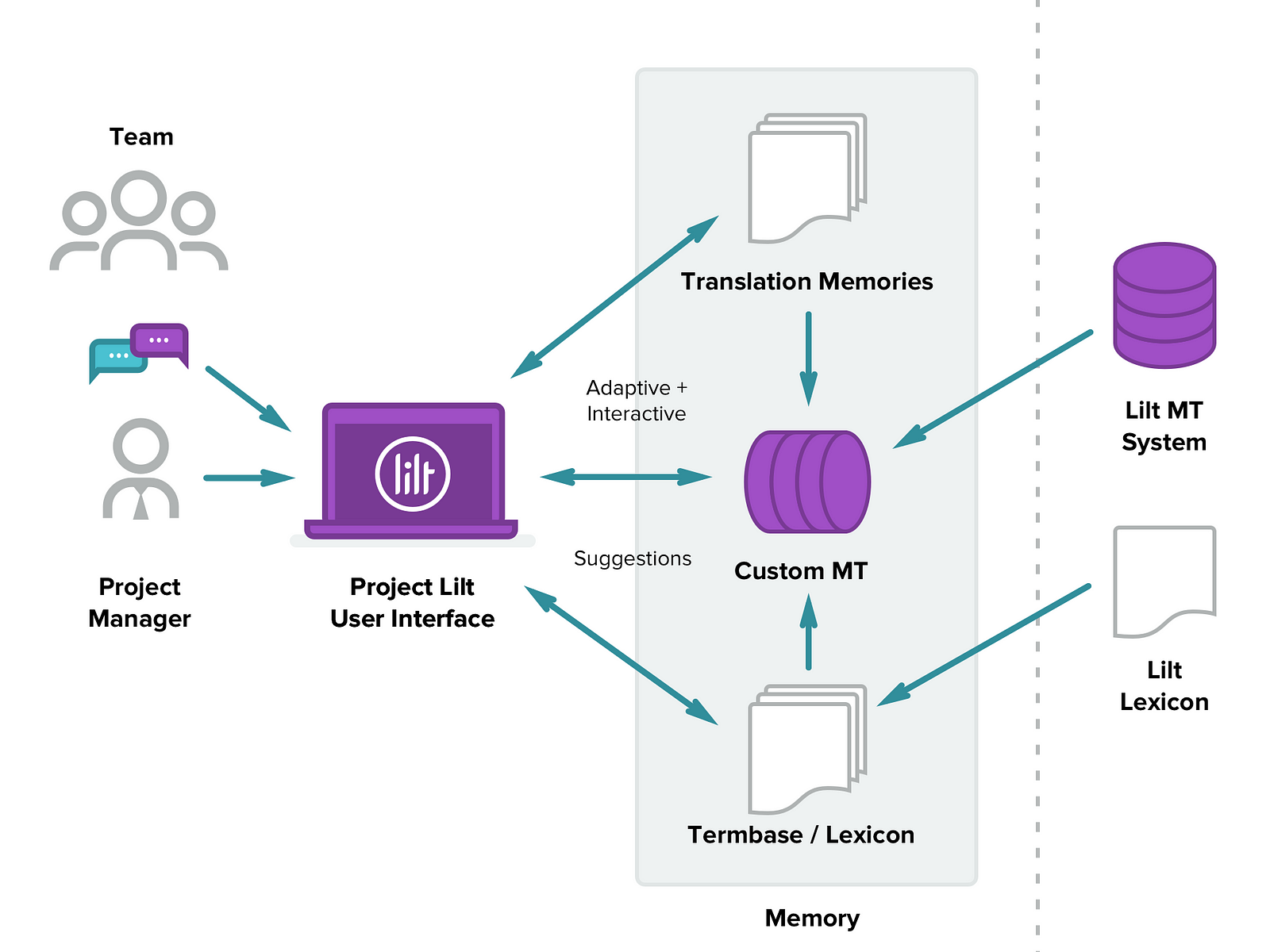
Our new advanced termbase editor lets you manage terminology more effectively by keeping terms organized with meta information that you can customize. Import terminology with meta fields or add your own fields. Your terms will appear in both the Lexicon and the Editor suggestions and help you increase consistency and quality.
In a world where data hacks and breaches seem to make front-page news more often than we’d like, a common question translators and businesses have about Lilt is usually: is my data safe? No need to worry. Lilt was built with that concern in mind. Read the answers below to some common questions about security in Lilt. Is my data shared with anyone? Your data is private to your Lilt account. It is never shared with other accounts and/or users. When you upload a translation memory or translate a document, those translations are only associated with your account. For Business customers, translation memories can be shared across your projects, but they are not shared with other users or third parties.
Ever wonder what happens in the process of translation/interpretation “under the hood?” Let’s look at the mode of interpretation first. Cognitive processes that take place in a simultaneous interpreter’s mind and brain are intense and all happening nearly at the same time. Neurons are firing in all directions, igniting different cognitive processing circuitry. The brain is literally “on fire,” as a Russian cognitive scientist puts it. Consecutive interpreting is different from simultaneous from the perspective of the cognitive science, in that the stages of conversion of meaning and reproduction are delayed from the stage of intake and deciphering of the message. That does not, however, make the process easier.
A major problem in effective deployment of machine learning systems in practice is domain adaptation — given a large auxiliary supervised dataset and a smaller dataset of interest, using the auxiliary dataset to increase performance on the smaller dataset. This paper considers the case where we have K datasets from distinct domains and adapting quickly to a new dataset. It learns K separate models on each of the K datasets and treats each as experts. Then given a new domain it creates another model for this domain, but in addition, computes attention over the experts. It computes attention via a dot product that computes the similarity of the new domain’s hidden representation with the other K domains’ representations.
Lilt was designed to maximize translation productivity. So you’ll want to get started using quickly, rather than spending your time learning how to use it. The interface and user experience differ from conventional CAT tools. Change is hard. We know. But we’ve designed the system with the goal of making you productive in less than 10 minutes. The articles in our Knowledge Base will turn you into a power user, but here are the basics of what you need to know to get started…
When doing beam search in sequence to sequence models, one explores next words in order of their likelihood. However, during decoding, there may be other constraints we have or objectives we wish to maximize. For example, sequence length, BLEU score, or mutual information between the target and source sentences. In order to accommodate these additional desiderata, the authors add an additional term Q onto the likelihood capturing the appropriate criterion and then choose words based on this combined objective.
Originally posted on LinkedIn by Greg Rosner. I saw the phrase “linguistic janitorial work” in this Deloitte whitepaper on “AI-augmented government, using cognitive technologies to redesign public sector work”, used to describe the drudgery of translation work that so many translators are required to do today through Post-editing of Machine Translation. And then it hit me what’s really going on. The sad reality over the past several years is that many professional linguists, who have decades of particular industry experience, expertise in professional translation and have earned degrees in writing, whose jobs have been reduced to sentence-by-sentence clean-up of translations that flood out of Google Translate or other Machine Translation (MT) systems.
Written by Kelly Messori The idea that robots are taking over human jobs is by no means a new one. Over the last century, the automation of tasks has done everything from making a farmer’s job easier with tractors to replacing the need for cashiers with self-serve kiosks. More recently, as machines are getting smarter, discussion has shifted to the topic of robots taking over more skilled positions, namely that of a translator. A simple search on the question-and-answer site Quora reveals dozens of inquiries on this very issue. While a recent survey shows that AI experts predict that robots will take over the task of translating languages by 2024. Everyone wants to know if they’ll be replaced by a machine and more importantly, when will that happen?