
Originally published on Kirti Vashee’s blog eMpTy Pages.
Lilt is an interactive and adaptive computer-aided translation tool that integrates machine translation, translation memories, and termbases into one interface that learns from translators. Using Lilt is an entirely different experience from post-editing machine translations — an experience that our users love, and one that yields substantial productivity gains without compromising quality. The first step toward using this new kind of tool is to understand how interactive and adaptive machine assistance is different from conventional MT, and how these technologies relate to exciting new developments in neural MT and deep learning.
Interactive MT doesn’t just translate each segment once and leave the translator to clean up the mess. Instead, each word that the translator types into the Lilt environment is integrated into a new automatic translation suggestion in real time. While text messaging apps autocomplete words, interactive MT autocompletes whole sentences. Interactive MT actually improves translation quality. In conventional MT post-editing, the computer knows what segment will be translated, but doesn’t know anything about the phrasing decisions that a translator will make. Interactive translations are more accurate because they can observe what the translator has typed so far and update their suggestions based on all available information.
Even the first few words of a translation provide strong cues about the intended structure of a sentence, and the Lilt system reacts in a fraction of a second to each word, which provides a significant productivity boost. Lilt and Stanford researchers published the best method yet for making accurate interactive translation suggestions in their 2016 Association for Computational Linguistics paper, Models and Inference for Prefix-Constrained Machine Translation. Often when using interactive MT, correcting the first part of a translation is all that is required; the rest is corrected automatically by the system, which follows the lead of the translator.
While interactive MT improves suggestions within a segment, adaptive MT works across segments. Lilt’s adaptive assistance learns automatically from translators in real time as they work, so that any errors made in one segment and corrected by the translator are typically not repeated in later segments. By contrast, a conventional MT system such as Google Translate always returns the same translation for the same segment and often repeats mistakes, which must be corrected each time. Custom MT, built for example by Microsoft Translator Hub, learns from example translations that are specific to a project or client, and this additional training can improve quality substantially. However, custom MT does not continue to adapt as translators work; instead it must be retrained periodically when new projects are completed. Lilt’s adaptive MT does not require retraining at all because it learns automatically from each segment that is confirmed by a translator. When a group of translators collaborate on a large project, each confirmed segment is integrated into the translation engine, so that suggestions given to all teammates are improved each time anyone confirms a segment. Each update takes less than a half of a second. When using adaptive MT, translators find that the suggestions improve as they progress through a document because the system has learned how they translated the first part of the document when suggesting translations for the rest. Much like interactive MT, adaptive MT uses all available information to make the best suggestions possible.
Machine translation, translation memories, and termbases have conventionally been three isolated sources of information that translators have to merge together manually. Lilt combines all three sources automatically. A translation memory provides exact and partial matches, but is also used to automatically customize machine translation suggestions. A termbase is used to ensure terminological consistency, even within the automatic suggestions generated by the interactive translation engine. An integrated lexicon panel includes public bilingual dictionaries and project-specific terms, along with concordance search that automatically merges together examples from public corpora and translation memory matches. Lexicon and concordance matches are ranked for relevancy using neural network models of word and sentence similarity. These neural models learn automatically from usage to detect which words in a document are inflected or derived forms of terms in a user’s termbase, discovering patterns of both inflectional and derivational morphology. Integrated use of all the data relevant to translation not only improves accuracy and efficiency, but actually reduces the amount of configuration required to use the system. Translators simply add all relevant resources to Lilt when starting a project, and all of it is used together to optimize the interface and suggestions during translation, lexicon lookup, and concordance search.
One of the most exciting new developments in the field of machine translation is neural MT. For the first time, neural systems are able to discover similarities between related words and phrases, and whole sentences are generated coherently instead of being pieced together from small independent fragments. The quality of the best neural translation systems exceeds those of conventional statistical systems by a large margin, often cleaning up agreement and sentence structure errors that have persisted in MT systems for many years. These gains are available even in a conventional post-editing setting.
Quality gains from interactive and adaptive translation are often larger than the gains from switching to neural MT, which is not surprising — interactive and adaptive translation can utilize new information from the translator. However, the most exciting discovery is that the gains from neural MT and interactive MT can be combined. In 2016, Lilt and Stanford researchers showed that using a neural translation system to autocomplete partial translations interactively can be extremely effective — correctly predicting the next word that a translator would type 53–55% of the time in software and news documents translated from English to German. Our research suggests that interactive translation has even more to gain from neural MT than conventional post-editing.
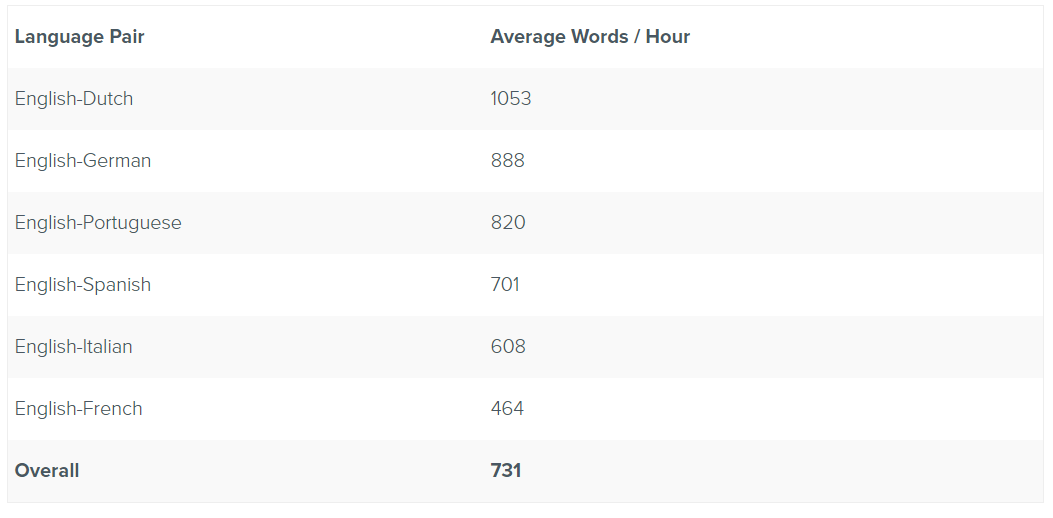
The combination of interactive and adaptive machine translation has proven particularly effective when large teams of translators are working under a tight deadline. In May 2016, the European travel portal GetYourGuide contracted e2f, based in California, to localize 1.77 million words from their catalog into 6 languages within a two-week window before summer travel began. More than 100 experienced translators contributed to the effort, using a shared Lilt adaptive MT engine for each language pair. The translators achieved speeds far above the industry average of 335 words per hour in all language pairs, and the project was completed ahead of schedule.
Lilt won the 2016 TAUS Innovation Excellence Award by replacing post-editing with interactive and adaptive machine assistance. This approach takes advantage of new discoveries in neural machine translation much more effectively than traditional MT. Moreover, this approach leaves translators in control of their workflow and provides a new integrated interface designed to make it easy to use this advanced technology. We believe that the future is bright for translators who adopt Lilt’s new way of combining machine translation, translation memories, and termbases — a future that is more enjoyable, more productive, and more focused on the aspects of translation that only humans can get right.



