Lilt continually invests in its systems design and deployment configurations to keep its machine translation fast and highly available. Here, we describe how we re-structured the code used to translate segments in batches in order to better parallelize the GPU resources available.
A System Reaches its Limits
When we first released our machine translation for our self-managed customers, translation was done through the use of Kubernetes (k8s) jobs. Each request to translate via our /translate endpoint was processed as a separate k8s job.
While the approach certainly worked, and was to an extent an elegant, minimal solution, we quickly found that customers with high throughput demands simply weren’t getting the performance they expected when calling the /translate endpoint en masse.
New nodes are provisioned dynamically on our Google Cloud Platform cluster (which hosts lilt.com) when none are available. This can take up to several minutes, especially for GPU nodes with low availability.
When a k8s job gets scheduled on a new node, the application's docker image (over 5 GB) has to be downloaded to the node. This could take over 60 seconds, a considerable amount of overhead for an API endpoint like /translate for which customers would expect faster results. Since each job processed only one request and then exited, spinning nodes up and down occurred so frequently as to exacerbate the overhead costs.
And, the overhead costs didn’t end with VM provisioning and overlaid k8s nodes.
Once a k8s job started, we incurred an additional overhead of about 9-14 seconds. This was related to tensorflow loading some libraries on container start and python initialization.
The jobs made no reuse of previously loaded objects, such as Lilt-specific word services and model files. Loading each of those could take a few seconds at the least.
Finally, and most critically: batch translation of multiple small documents as separate jobs was inefficient and sunk overall system throughput. For example, processing only a hundred tiny documents in the old system using 8 GPUs in parallel took minutes! The machine translation models themselves were fast, as when we concatenated the content of those tiny documents into one file and ran it on one GPU, the time was in seconds.
Improvement Strategy
To summarize, there were a few low-hanging fruit that we could pick by re-designing the system, some harder nuts to crack, and some system and software limitations hard to resolve with our time constraints.
- Use long-running workers that don’t exit after processing a single request. This allows them to re-use previously loaded objects, and amortizes the high start-up time.
- Use Kubernetes deployments for workers instead of jobs. The number of workers can then be dynamically adjusted by telling Kubernetes to change the number of replicas. The advantage is when a new version is released, often several times per week, old workers will be scaled down and new ones will be scaled up automatically. As a side benefit, our monitoring system, Prometheus, is able to directly scrape metrics from the workers.
- Develop a custom watchdog service to detect and act on worker-related failures and timeouts.
- If multiple small documents are sent for batch translation together, batch and process them together (not covered in this post).
Redesigned Architecture
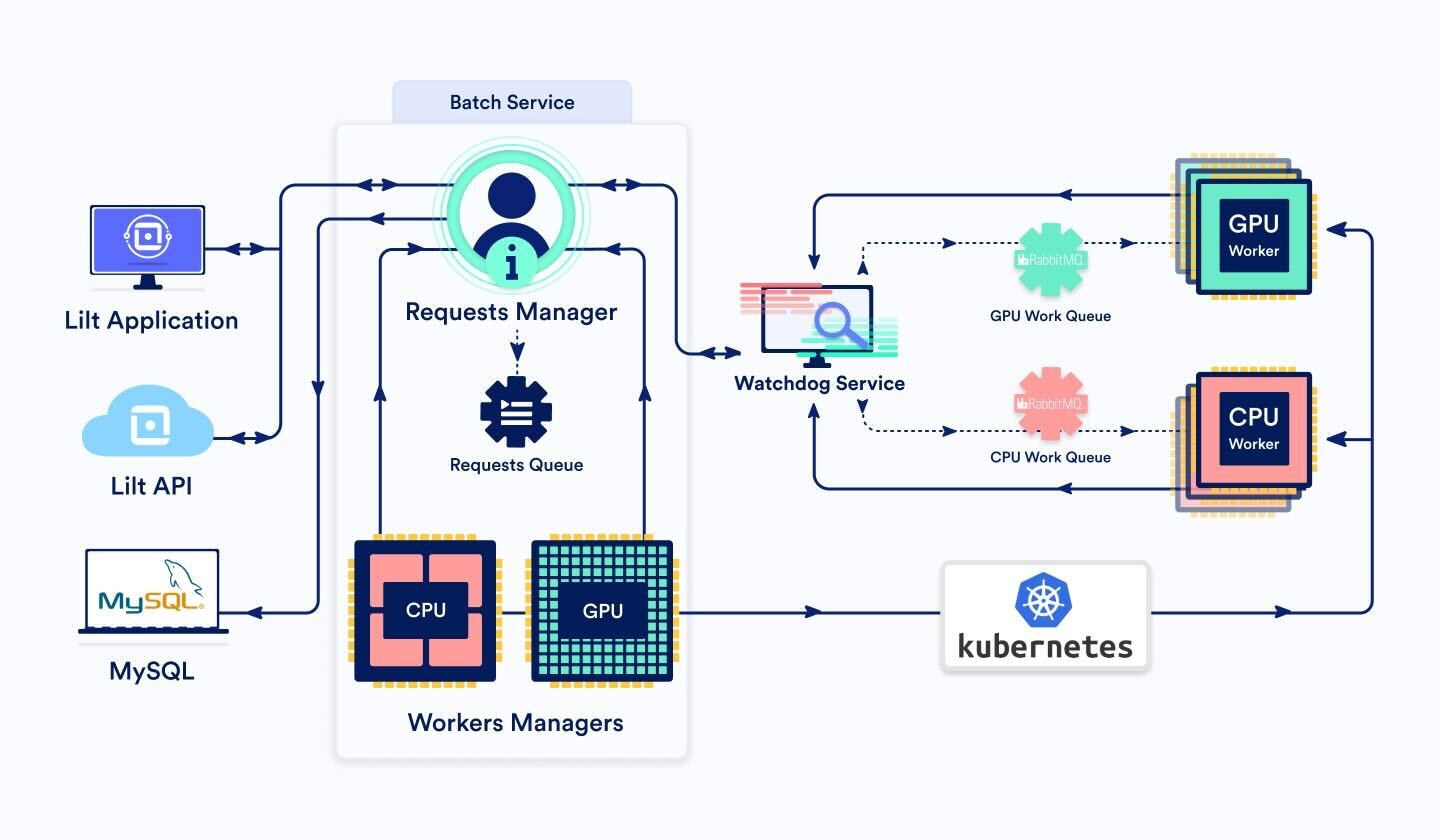
BatchService
This service is comprised of three main components:
BatchRequestsManager and BatchRequestsQueue
When a batch request comes in via the Lilt API or interface, the request is routed to the BatchRequestsManager. It determines if processing the request should be done by a GPU or CPU worker, based on the number of segments to be processed. As a general rule, when we have less than 3000 segments, we go to the CPU, otherwise to the GPU.
The manager generates a job ID and writes the job's details to the DB. This allows us to track the request through its lifetime.
Then, the job is added to the BatchRequestsQueue, a class maintaining the priority and order of pending requests.
Since the manager stores job state in the DB, on start-up it can be initialized with any queued and in-progress jobs.
If the number of jobs currently being processed by workers is less than the maximum number of workers -- meaning there’s room to take on more work -- a message is sent to the appropriate batch worker (either CPU or GPU) message queue through the Watchdog service. The BatchService updates the job's status in the DB to “submitted”.
When the job finishes, the manager cleans up temporary files and removes the job from the DB.
BatchWorkersManager
On our production services, the number of nodes and workers is variable. However, they don’t scale perfectly based on load. If the cluster has too few resources, processing batch requests is delayed by new worker startup time. If the cluster over-provisions resources, we waste money on idle workers.
Thus, a BatchWorkersManager class is necessary to fine-tune the number of workers available. It does this by calling the Kubernetes API to set the number of worker pod replicas. We have two instances of BatchWorkersManager, one for CPU and one for GPU workers.
The logic is as follows:
- Call BatchRequestsManager to get the number of jobs currently being processed by workers.
- Pad that number by a number of standby workers to allow for resource smoothing.
- Adjust the number so that it is within the hard cluster minimum and maximum.
- If reducing the number of replicas, wait X minutes first and then check again if a reduction is still desired. This smooths resource provision.
BatchWorker (dynamic number of pods)
BatchWorkers represent the smallest unit of resource in this system. When a BatchWorker fetches a message from the work message queue, it begins processing the request and periodically sends a heartbeat message to the Watchdog service to ensure the Watchdog doesn’t time it out.
Processing a request can take up to an unbounded length, depending on the number of segments that need translation, which can vary wildly. When it’s done, the BatchWorker sends a message via the Watchdog Service to the BatchService indicating the job is complete. It acks the request in rabbitmq, and proceeds to fetch the next message from the queue.
Note that when Kubernetes tries to terminate workers, for example after a new image release or reduction in the number of replicas, it gives the worker a grace period to finish processing its requests. We set this parameter, terminationGracePeriodSeconds, to a large value since we can’t ask Kubernetes to terminate a particular worker during scale-down. We thus give terminated workers the chance to finish processing existing requests. When the worker finishes processing requests, it shuts down.
Watchdog Service
The Watchdog service keeps an eye on asynchronous requests by providing failure and fault detection.
If service A (e.g., the Batch Service) wants to send a request to service B (e.g., a Batch Worker) but doesn't want to synchronously wait for a response (for example, because the response is expected to take a long time), it can send the request through the Watchdog Service, letting the Watchdog Service know what the target service is. The Watchdog Service will forward the request to the target service B. Service B must then send heartbeat messages to the Watchdog Service periodically to indicate the request is still active and in process. Once service B finishes processing the request, it sends a response back to the Watchdog Service. The Watchdog Service will then forward the response to the originating service A.
If the Watchdog Service doesn't receive heartbeat messages for a request for a certain amount of time, it will consider the request as failed, and send a failure message to the originating service A.
Because we need to support variable size requests (since the number of segments in the API call can vary widely, as is the nature of document data), it made sense to process them asynchronously and utilize the Watchdog Service.
Further Improvements
We can further elevate our machine translation throughput! Here are some ideas we’re considering for the next phase:
- Figure out a way to tell Kubernetes which workers to terminate when decreasing the number of replicas. For example, by picking the number of workers that aren't actively processing a request, or the ones with the smallest model caches. There currently doesn’t seem to be a way around this (see https://github.com/kubernetes/kubernetes/issues/45509).
- Split large documents into chunks and process the chunks in parallel using multiple workers.
- Return partial results during processing, so clients don't have to wait until the entire document is done.
- When distributing a request to the workers, have a way to prioritize distribution to a worker that's already previously downloaded and loaded the models and assets required for processing the language pair in the request. This can reduce the time it takes to process requests.