
Ursprünglich in Kirti Vashees Blog eMpTy Pages veröffentlicht.
Lilt ist ein interaktives und adaptives computergestütztes Übersetzungstool, das maschinelle Übersetzung, Translation Memories und Terminologiedatenbank in einer Benutzeroberfläche kombiniert und von Übersetzern lernt. Die Verwendung von Lilt ist eine völlig andere Erfahrung als das Post-Editing maschineller Übersetzungen, eine Erfahrung, die unsere Benutzer lieben, und eine, die erhebliche Produktivitätssteigerungen erzielt, ohne dabei Abstriche bei der Qualität zu machen. Der erste Schritt bei der Anwendung dieser neuen Art von Tool besteht darin, zu verstehen, wie interaktive und adaptive maschinelle Unterstützung sich von der herkömmlichen MT unterscheidet und wie diese Technologien zusammenhängen und zu aufregenden neuen Entwicklungen in der neuronalen MT und beim Deep Learning führen.
Interaktive MT übersetzt nicht nur jedes Segment einmal und überlässt dem Übersetzer dann die Aufgabe, das Ganze zu bereinigen. Stattdessen wird jedes Wort, das der Übersetzer in der Lilt-Umgebung eingibt, in Echtzeit in einen neuen automatischen Übersetzungsvorschlag integriert. Während Text-Messaging-Apps Wörter automatisch vervollständigen, vervollständigt interaktive MT ganze Sätze automatisch. Interaktive MT verbessert die Übersetzungsqualität wirklich. Beim herkömmlichen MT-Post-Editing weiß der Computer, welches Segment übersetzt wird, er weiß aber nichts über die Entscheidungen zum richtigen Ausdruck, die von einem Übersetzer getroffen werden. Interaktive Übersetzungen sind genauer, weil sie beobachten können, was der Übersetzer bisher eingegeben hat, und ihre Vorschläge auf der Grundlage aller verfügbaren Informationen aktualisieren können.
Selbst die ersten paar Wörter einer Übersetzung liefern gute Hinweise über die intendierte Satzstruktur, und das Lilt-System reagiert in einem Bruchteil einer Sekunde auf jedes Wort, was eine signifikante Produktivitätssteigerung ermöglicht. Forscher von Lilt und der Universität Stanford veröffentlichten in ihrer Publikation für die Association for Computational Linguistics 2016 Models and Inference for Prefix-Constrained Machine Translation die bislang beste Methode, um präzise interaktive Übersetzungsvorschläge zu machen. Wenn interaktive MT verwendet wird, muss oft nur der erste Teil einer Übersetzung korrigiert werden, der Rest wird vom System automatisch korrigiert, das den Vorgaben des Übersetzers folgt.
Während interaktive MT die Vorschläge innerhalb eines Segments verbessert, funktioniert adaptive MT segmentübergreifend. Die adaptive Unterstützung von Lilt lernt in Echtzeit automatisch von der Arbeit der Übersetzer, sodass alle Fehler in einem Segment, die vom Übersetzer korrigiert wurden, normalerweise in späteren Segmenten nicht wiederholt werden. Im Gegensatz dazu gibt ein herkömmliches MT-System wie Google Translate immer die gleiche Übersetzung für das gleiche Segment zurück und wiederholt oft Fehler, die dann jedes Mal korrigiert werden müssen. Spezifisch angepasste MT, wie sie beispielsweise von der Microsoft Translator Hub bereitgestellt wird, lernt aus Beispielübersetzungen, die für ein Projekt oder einen Kunden spezifisch sind. Durch dieses zusätzliche Training kann die Qualität erheblich verbessert werden. Spezifisch angepasste MT passt sich aber nicht weiter während der Arbeit der Übersetzer an. Stattdessen muss sie regelmäßig neu trainiert werden, wenn neue Projekte abgeschlossen werden. Die adaptive MT von Lilt erfordert überhaupt kein erneutes Training, da sie automatisch aus jedem Segment lernt, das von einem Übersetzer bestätigt wird. Wenn eine Gruppe von Übersetzern an einem großen Projekt zusammenarbeitet, wird jedes bestätigte Segment in die Übersetzungs-Engine integriert, sodass die allen Teammitgliedern gegebenen Vorschläge sich jedes Mal verbessern, wenn jemand ein Segment bestätigt. Jede Aktualisierung dauert weniger als eine halbe Sekunde. Bei der Verwendung von adaptiver MT stellen Übersetzer fest, dass die Vorschläge im Lauf der Übersetzung eines Dokuments immer besser werden, weil das System gelernt hat, wie sie den ersten Teil des Dokuments übersetzt haben, wenn es Übersetzungen für den Rest vorschlägt. Wie interaktive MT verwendet adaptive MT alle verfügbaren Informationen, um optimale Vorschläge zu machen.
Maschinelle Übersetzung, Translation Memories und Terminologiedatenbanken waren bislang drei isolierte Informationsquellen, die Übersetzer manuell zusammenführen mussten. Lilt kombiniert alle drei Quellen automatisch. Ein Translation Memory liefert exakte und teilweise Übereinstimmungen, wird aber auch verwendet, um die Vorschläge der maschinellen Übersetzung automatisch anzupassen. Eine Terminologiedatenbank oder Termbase wird verwendet, um eine einheitliche Terminologie sicherzustellen, und zwar auch innerhalb der automatischen, von der interaktiven Übersetzungs-Engine generierten Vorschläge. Ein integrierter Lexikon-Bereich enthält öffentliche zweisprachige Wörterbücher und projektspezifische Begriffe sowie die Konkordanzsuche, die automatisch weitere Beispiele aus öffentlichen Korpora und Translation-Memory-Übereinstimmungen zusammenführt. Lexikon und Konkordanztreffer werden mithilfe neuronaler Netzwerkmodelle der Wort- und Satzähnlichkeit nach der Relevanz eingestuft Diese neuronalen Modelle lernen automatisch aus der Übersetzung, um festzustellen, welche Wörter in einem Dokument gebeugte oder abgeleitete Formen von Begriffen in der Terminologiedatenbank eines Benutzers sind. Sie entdecken dabei Muster der sowohl Beugungs- als auch Ableitungs-Morphologie. Die integrierte Verwendung aller für die Übersetzung relevanten Daten verbessert nicht nur die Genauigkeit und Effizienz, sondern reduziert auch den für die Verwendung des Systems erforderlichen Konfigurationsaufwand. Übersetzer fügen alle relevanten Ressourcen einfach Lilt hinzu, wenn sie ein Projekt starten, und sie alle werden zusammen verwendet, um die Benutzeroberfläche und Vorschläge während der Übersetzung, die Lexikon- und Konkordanzsuche zu optimieren.
Eine der spannendsten Neuentwicklungen im Bereich der maschinellen Übersetzung ist neuronale MT. Erstmals können neuronale Systeme Ähnlichkeiten zwischen verwandten Wörtern und Phrasen entdecken und ganze Sätze kohärent generiert werden, anstatt sie aus kleinen unabhängigen Fragmenten zusammenzusetzen. Die Qualität der besten neuronalen Übersetzungssysteme übersteigt die herkömmlicher statistischer Systeme bei weitem. Übereinstimmungs- und Satzstrukturfehler, die seit vielen Jahren in MT-Systemen andauern, werden dabei oft behoben. Diese Verbesserungen sind selbst in einer herkömmlichen Post-Editing-Situation verfügbar.
Qualitätsverbesserungen aus der interaktiven und adaptiven Übersetzung sind oft größer als die Gewinne der Umstellung auf neuronale MT, was nicht verwunderlich ist: Interaktive und adaptive Übersetzung können neue Informationen vom Übersetzer verwenden. Die interessanteste Entdeckung ist aber, dass die Verbesserungen durch neuronale MT und interaktive MT kombiniert werden können. 2016 zeigten Forscher von Lilt und der Universität Stanford, dass die Verwendung eines neuronalen Übersetzungssystems zur interaktiven automatischen Vervollständigung von Teilübersetzungen extrem effektiv sein kann und das neue Wort, das ein Übersetzer eingeben würde, in Software- und Nachrichtendokumenten, die aus dem Englischen ins Deutsche übersetzt wurden, in 53–55 % der Fälle richtig vorhersagen konnte. Unsere Forschung legt nahe, dass interaktive Übersetzung noch mehr von neuronaler MT profitieren kann als herkömmliches Post-Editing.
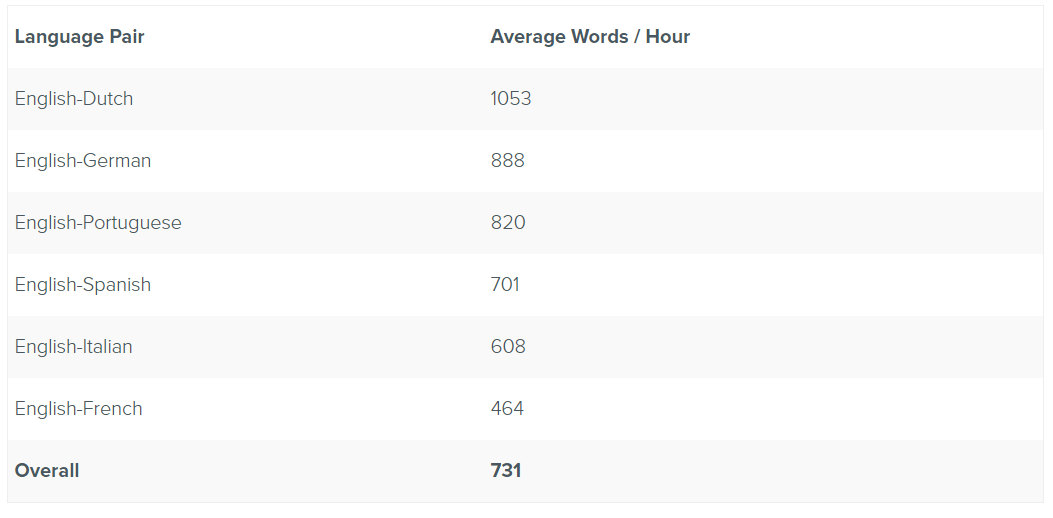
Die Kombination aus interaktiver und adaptiver maschineller Übersetzung hat sich besonders bewährt, wenn große Teams von Übersetzern unter starkem Termindruck arbeiten. Im Mai 2016 beauftragte das europäische Reiseportal GetYourGuide e2f mit Sitz in Kalifornien, 1,77 Millionen Wörter aus seinem Katalog innerhalb von zwei Wochen vor Beginn der Sommerreisesaison in sechs Sprachen zu lokalisieren. Mehr als 100 erfahrene Übersetzer trugen zu dem Projekt bei und verwendeten eine gemeinsame adaptive Lilt-MT-Engine für jedes Sprachpaar. Die Übersetzer erzielten Geschwindigkeiten, die in allen Sprachen weit über den Branchendurchschnitt von 335 Wörtern pro Stunde hinausgingen, und das Projekt wurde vor dem Termin abgeschlossen.
Lilt wurde mit dem TAUS Innovation Excellence Award 2016 ausgezeichnet, indem es Post-Editing mit interaktiver und adaptiver maschineller Unterstützung ersetzte. Dieser Ansatz nutzt neue Entdeckungen in der neuronalen maschinellen Übersetzung viel effektiver als herkömmliche MT. Darüber haben Übersetzer bei diesem Ansatz die Kontrolle über ihren Workflow und er bietet eine neue integrierte Schnittstelle, die die Verwendung dieser fortschrittlichen Technologie einfach macht. Wir sind der Meinung, dass die Zukunft für Übersetzer, die Lilts neue Methoden zur Kombination von maschineller Übersetzung, Translation Memories und Terminologiedatenbanken einsetzen, angenehmer, produktiver und mehr auf die Aspekte der Übersetzung konzentriert sein wird, die nur Menschen richtig hinbekommen.