
Lilt investiert kontinuierlich in sein Systemdesign und die Konfigurationen für die Implementierung, sodass seine maschinellen Übersetzungen immer zeitnah und mit hoher Verfügbarkeit abrufbar sind. Im Folgenden beschreiben wir, wie der Code neu strukturiert wurde, um Segmente in Chargen zu übersetzen, sodass die GPU-Ressourcen besser parallelisiert werden können.
Ein System erreicht seine Grenzen
Als wir unser System für maschinelle Übersetzungen zum ersten Mal unseren eigenverwalteten Kunden vorgestellt haben, erfolgten die Übersetzungen über Kubernetes-Aufträge (k8s). Jeder Übersetzungsauftrag über unseren /translate-Endpunkt wurde als separater k8s-Auftrag bearbeitet.
Während dieser Ansatz sicherlich gut funktionierte und in einem gewissen Umfang auch eine elegante Minimallösung war, stellten wir schnell fest, dass Kunden mit hohen Durchsatzanforderungen einfach nicht auf die Leistung zugreifen konnten, die sie bei einem Aufruf des /translate-Endpunkts in großem Umfang erwarteten.
Neue Knoten werden dynamisch in unserem Google Cloud Platform Cluster (in dem lilt.com gehostet wird) bereitgestellt, wenn keine verfügbar sind. Dies kann manchmal bis zu mehrere Minuten dauern, insbesondere bei GPU-Knoten mit geringer Verfügbarkeit.
Wenn ein k8s-Auftrag auf einem neuen Knoten anberaumt wird, muss das sogen. Docker Image (über 5 GB) der Anwendung zum Knoten heruntergeladen werden. Das dauerte u. U. mehr als 60 Sekunden – ein ziemlicher Aufwand für einen API-Endpunkt wie /translate, bei dem Kunden schnellere Ergebnisse erwarten würden. Da jeder Auftrag immer nur eine Anfrage bearbeitet hat und dann beendet wurde, nahmen die Overhead-Kosten durch das Hoch- und Herunterfahren der Knoten drastisch zu.
Und diese Overhead-Kosten endeten nicht mit der VM-Bereitstellung und überlagerten k8s-Knoten.
Wenn ein k8s-Auftrag einmal begann, trat ein zusätzlicher Overhead von etwa 9 bis 14 Sekunden auf. Dies stand in direktem Zusammenhang damit, dass TensorFlow beim Container-Start und bei der Python-Initialisierung einige Bibliotheken geladen hat.
Bei diesen Aufträgen wurden zuvor geladene Objekte wie Lilt-spezifische Wortfunktionen und Modelldateien nicht wiederverwendet. Der Ladevorgang dieser Komponenten konnte manchmal einige Sekunden in Anspruch nehmen.
Und schließlich (was eigentlich am wichtigsten war): Die Batchverarbeitung der Übersetzung von mehreren kleinen Dokumenten als separate Aufträge war ineffizient und zog den Gesamtdurchsatz des Systems nach unten. Zum Beispiel dauerte die parallele Bearbeitung von nur hundert winzigen Dokumenten mit dem alten System mit 8 GPUs Minuten! Die MT-Modelle selbst waren schnell, wie bei der Verknüpfung des Inhalts dieser winzigen Dokumente zu einer Datei. Wenn wir diese mit einer GPU bearbeiteten, dauerte es nur Sekunden.
Verbesserungsstrategien
Zusammenfassend kann man sagen, dass es wenige einfache umzusetzende Maßnahmen gab, die uns für das neue Systemdesign zur Verfügung standen, einige wirklich harte Nüsse und System- und Softwareeinschränkungen, die angesichts der begrenzten Zeit, die uns blieb, schwer zu lösen waren.
- Verwendung von Arbeitsmaschinen, die lange laufen und nach der Bearbeitung einer einzigen Anfrage nicht inaktiv werden. So können zuvor geladene Objekte wiederverwendet und die lange Zeit besser genutzt werden.
- Verwendung von Kubernetes-Implementierungen für Arbeitsmaschinen und nicht für Aufträge. Die Anzahl der Arbeitsmaschinen kann dann dynamisch angepasst werden, indem man Kubernetes aufträgt, die Anzahl der Replikate zu ändern. Der Vorteil besteht darin, dass bei Veröffentlichung einer neuen Version – d. h. oft mehrmals pro Woche – alte Arbeitsmaschinen automatisch nach unten und neue nach oben skaliert werden. Und als zusätzlicher Vorteil kann unser Überwachungssystem Prometheus die Kennzahlen der Arbeitsmaschinen direkt abfragen.
- Entwicklung eines benutzerdefinierten Watchdog-Service zur Erkennung und Behebung von Ausfällen und Zeitfehlern von Arbeitsmaschinen.
- Wenn mehrere kleine Dokumente zusammen für die Batch-Übersetzung eingereicht werden, werden diese zu Batches kombiniert und zusammen verarbeitet (dieses Thema wird in diesem Beitrag nicht abgedeckt).
Neugestaltete Architektur
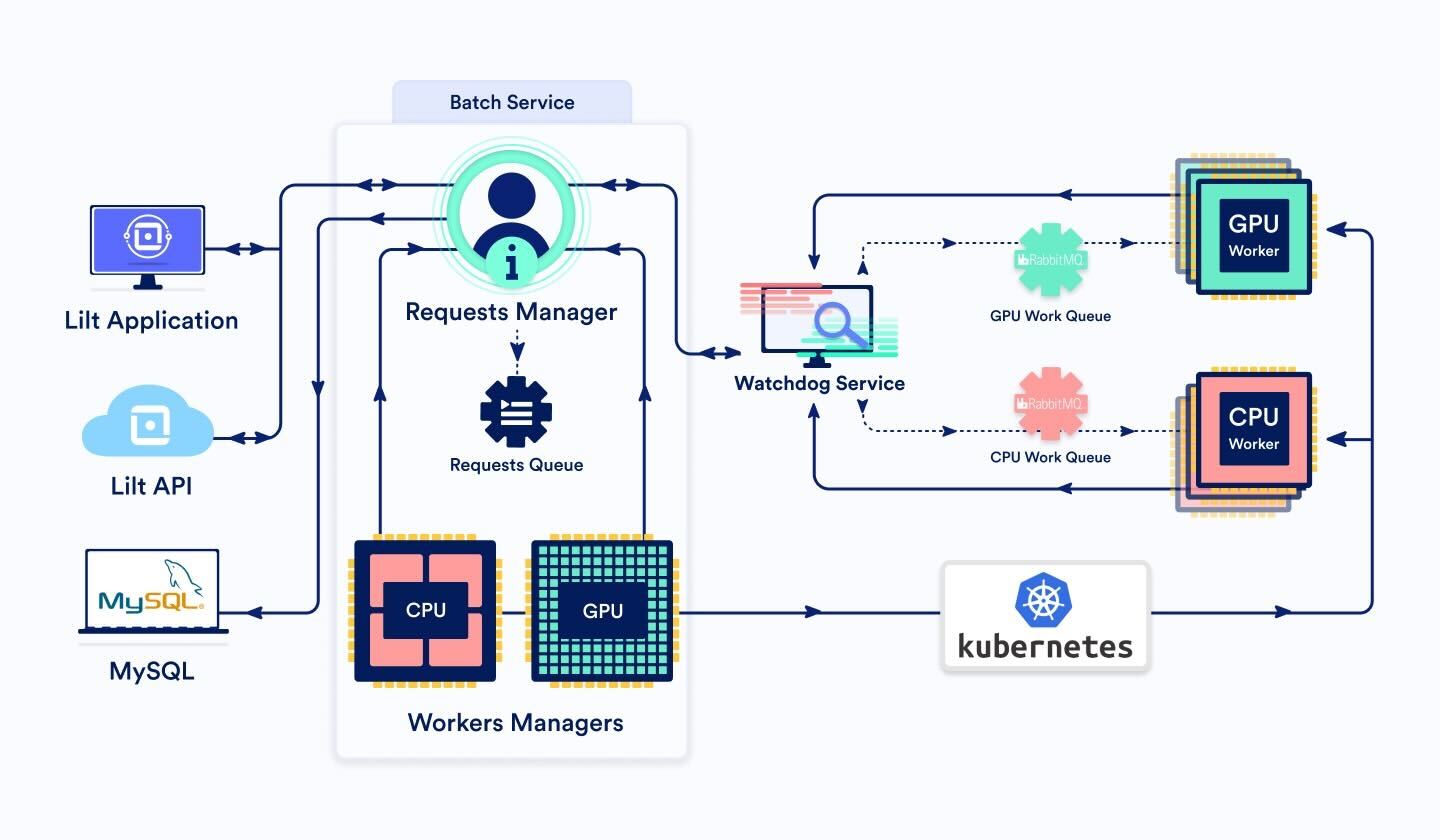
Batch-Service
Dieser Service besteht aus drei Hauptkomponenten:
BatchRequestsManager und BatchRequestsQueue
Wenn eine Batch-Anfrage über die Lilt-API oder -Schnittstelle eintrifft, wird sie zum BatchRequestsManager weitergeleitet. Dieser legt fest, ob die Anfrage über eine GPU- oder CPU-Arbeitsmaschine erfolgen soll, und zwar auf Grundlage der zu bearbeitenden Segmente. Allgemein kann gesagt werden, dass bei weniger als 3000 Segmenten die CPU eingeschaltet wird. Ansonsten geht der Auftrag an die GPU.
Der Manager erstellt eine Auftrags-ID und trägt die Auftragsdaten in die DB ein. So kann der Antrag von Anfang an und bis zur Fertigstellung verfolgt werden.
Anschließend wird der Auftrag der BatchRequestsQueue hinzugefügt, einer Funktion, die die Priorität und Reihenfolge der anstehenden Anfragen beibehält.
Da der Manager den Auftragsstatus in der DB speichert, kann dieser bei der Inbetriebnahme mit jedem beliebigen Auftrag in der Warteschlange oder in der laufenden Bearbeitung initialisiert werden.
Wenn die Anzahl der Aufträge, die zurzeit von Arbeitsmaschinen verarbeitet werden, kleiner ist als die maximale Anzahl an Arbeitsmaschinen (d. h. es ist Platz für mehr Arbeit), wird über den Watchdog-Service eine Nachricht an die entsprechende Nachrichten-Warteschlange der Batch-Arbeitsmaschine geschickt (entweder CPU oder GPU). Mit BatchService wird der Auftragsstatus in der DB auf „eingereicht“ aktualisiert.
Ist der Auftrag fertiggestellt, bereinigt der Manager die temporären Dateien und entfernt den Auftrag aus der DB.
BatchWorkersManager
Die Anzahl der Knoten und Arbeitsmaschinen in unserer Produktionsabteilung variiert. Sie werden jedoch nicht perfekt auf der Grundlage der Last skaliert. Hat ein Cluster zu wenig Ressourcen, verzögert sich die Bearbeitung von Batch-Anfragen durch die neue Arbeitsmaschinen-Startzeit. Stellt ein Cluster zu viele Ressourcen bereit, verschwenden wir Geld mit Arbeitsmaschinen, die nicht gebraucht werden.
Von daher ist eine BatchWorkersManager-Funktion notwendig, um die Anzahl der verfügbaren Arbeitsmaschinen zu optimieren. Diese Optimierung erfolgt über einen Aufruf der Kubernetes-API, um die Anzahl der Arbeitsmaschinen-Pod-Replikate festzulegen. Es gibt zwei Instanzen des BatchWorkersManagers – eine für CPU- und eine für GPU-Arbeitsmaschinen.
Die zugrundeliegende Logik ist wie folgt:
- Der BatchRequestsManager wird aufgerufen, um die Anzahl der zurzeit von Arbeitsmaschinen verarbeiteten Aufträge zu erhalten.
- Diese Zahl wird durch die Anzahl an Standby-Arbeitsmaschinen aufgestockt, sodass immer ausreichend, aber nie zu wenig Ressourcen vorhanden sind.
- Die Anzahl wird dahingehend angepasst, dass sie in den Bereich zwischen dem absoluten Cluter-Minimum und -Maximum fällt.
- Bei der Reduzierung der Anzahl der Replikate ist erst X Minuten zu warten und dann erneut zu prüfen, ob eine Reduzierung noch gewünscht wird. Dies optimiert die Ressourcenbereitstellung.
BatchWorker (dynamische Pod-Anzahl)
BatchWorkers stellen die kleinste Ressourceneinheit in diesem System dar. Wenn ein BatchWorker eine Nachricht aus der Nachrichten-Warteschlange abruft, beginnt die Bearbeitung der Anfrage. Mit einer regelmäßigen Heartbeat-Nachricht an den Watchdog-Service wird sichergestellt, dass der Watchdog das Zeitlimit nicht überschreitet.
Die Bearbeitung einer Anfrage kann unbegrenzt lange dauern. Dies richtet sich nach der Anzahl der Segmente, die übersetzt werden müssen. Und diese kann stark variieren. Zum Schluss sendet der BatchWorker eine Nachricht über den Watchdog-Service an den BatchService als Hinweis dafür, dass der Auftrag abgeschlossen ist. Die Anfrage wird in RabbitMQ verfolgt und anschließend wird die nächste Nachricht aus der Warteschlange abgerufen.
Wenn Kubernetes versucht, Arbeitsmaschinen zu terminieren – zum Beispiel nach Veröffentlichung eines neuen Image oder nach Reduzierung der Anzahl von Replikaten – erhalten Arbeitsmaschinen eine Kulanzzeit, um die Bearbeitung der Anfragen zu beenden. Wir stellen diesen Parameter, TerminationGracePeriodSeconds, auf einen recht großen Wert ein, da wir Kubernetes nicht auffordern können, während der Herunterskalierung eine bestimmte Arbeitsmaschine zu terminieren. Wir geben terminierten Arbeitsmaschinen somit die Chance, bestehende Anfragen ganz abzuschließen. Sobald die Arbeitsmaschine die Bearbeitungsanfragen abgeschlossen hat, wird sie heruntergefahren.
Watchdog-Service
Der Watchdog-Service überwacht die asynchronen Anfragen anhand einer Ausfall- und Fehlererkennung.
Wenn Service A (z. B. der Batch-Service) eine Anfrage an Service B senden möchte (z. B. eine Batch-Arbeitsmaschine), aber nicht gleichzeitig auf eine Antwort warten möchte (z. B. weil zu erwarten ist, dass die Antwort sehr lange auf sich warten lassen wird), kann die Anfrage über den Watchdog-Service eingereicht werden und der Watchdog-Service darüber informiert werden, was der Ziel-Service ist. Der Watchdog-Service leitet die Anfrage an den Ziel-Service B weiter. Service B muss dann regelmäßig eine Heartbeat-Nachricht an den Watchdog-Service senden als Hinweis, dass die Anfrage noch aktiv ist und in Bearbeitung ist. Sobald Service B die Bearbeitung der Anfrage beendet hat, wird eine Antwort an den Watchdog-Service gesendet. Der Watchdog-Service leitet die Antwort dann an Service A weiter, von dem die Anfrage ursprünglich stammte.
Geht beim Watchdog-Service für eine gewisse Zeit lang keine Heartbeat-Nachricht für eine Anfrage ein, wird die Anfrage als fehlgeschlagen betrachtet und eine entsprechende Fehlernachricht an Service A gesendet.
Da wir Anfragen unterschiedlicher Größe unterstützen müssen (da die Anzahl der Segmente im API-Aufruf stark variieren kann, was bei Dokumentdaten zu erwarten ist), war es sinnvoll, diese asynchron zu verarbeiten und den Watchdog-Service zu nutzen.
Weitere Verbesserungen
Wir können den Durchsatz unserer maschinellen Übersetzungsleistung noch weiter steigern! Hier sind einige Ideen, die wir für die nächste Phase in Betracht ziehen:
- Entwicklung eines Konzepts, wie wir Kubernetes mitteilen können, welche Arbeitsmaschinen terminiert werden, wenn die Anzahl der Replikate abnimmt – zum Beispiel, indem wir die Anzahl der Arbeitsmaschinen auswählen, die Anfragen nicht aktiv bearbeiten (oder diejenigen mit den kleinsten Model Cache). Es gibt anscheinend zurzeit keine Möglichkeit, dies zu vermeiden (siehe https://github.com/kubernetes/kubernetes/issues/45509).
- Splitten von großen Dokumenten in kleine Teile und Verarbeitung der Teile parallel mit mehreren Arbeitsmaschinen.
- Anzeige von Zwischenergebnissen während der Bearbeitung, damit Kunden nicht warten müssen, bis die Übersetzung des gesamten Dokuments fertiggestellt ist.
- Bei der Vergabe einer Anfrage an Arbeitsmaschinen bietet sich die Priorisierung an eine Maschine an, die die Modelle und Inhalte bereits heruntergeladen und geladen hat, die für die Bearbeitung des Sprachenpaars für die Anfrage erforderlich sind. So kann der Zeitaufwand für die Bearbeitung der Anfragen verkürzt werden.