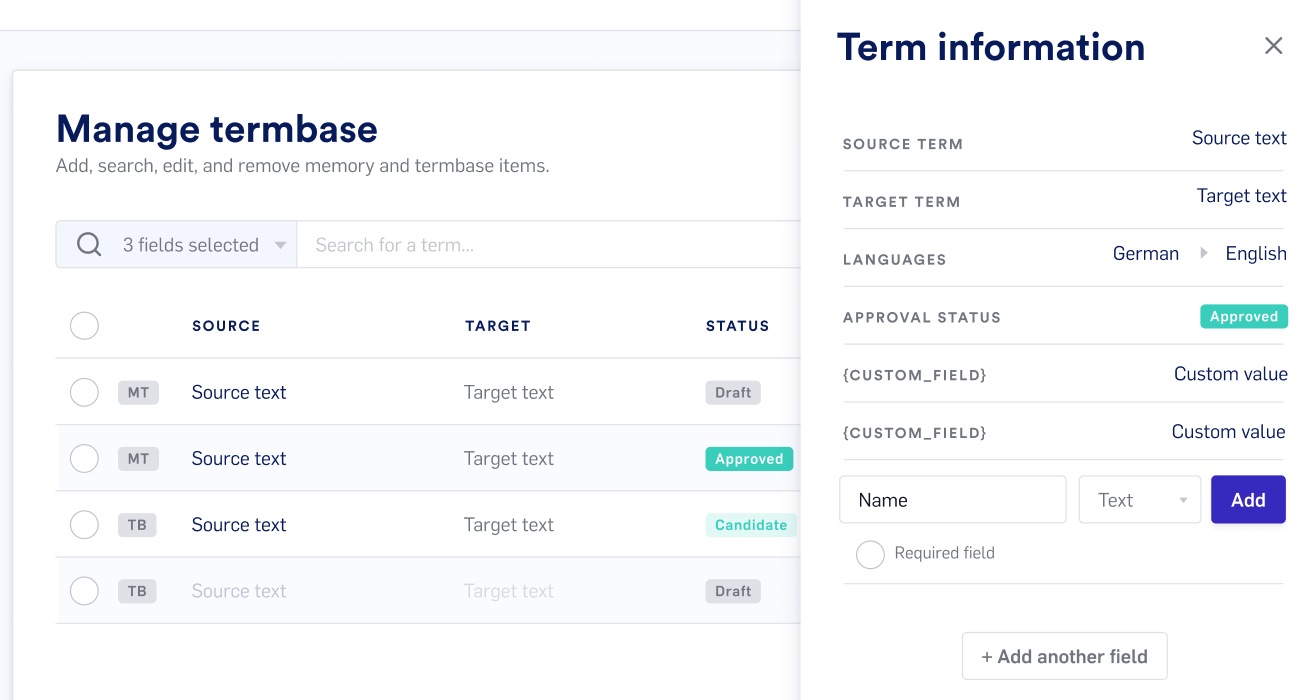
Our new advanced termbase editor lets you manage terminology more effectively by keeping terms organized with meta information that you can customize.
Import terminology with meta fields or add your own fields. Your terms will appear in both the Lexicon and the Editor suggestions and help you increase consistency and quality.
Our own Carmen Heger hosted a webinar to show you how to make the most of the termbase in Lilt. Check it out!