This post is an addendum to our original post on 1/10/2017 entitled 2017 Machine Translation Quality Evaluation.
Experimental Design
We evaluate all machine translation systems for English-French and English-German. We report case-insensitive BLEU-4 [2], which is computed by the mteval scoring script from the Stanford University open source toolkit Phrasal. NIST tokenization was applied to both the system outputs and the reference translations.We simulate the scenario where the translator translates the evaluation data sequentially from the beginning to the end. We assume that she makes full use of the resources the corresponding solutions have to offer by leveraging the translation memory as adaptation data and by incremental adaptation, where the translation system learns from every confirmed segment.
System outputs and scripts to automatically download and split the test data are available at: https://github.com/lilt/labs.
System Training
Production API keys and systems are used in all experiments. Since commercial systems are improved from time to time, we record the date on which the system outputs were generated.
Lilt
The Lilt baseline system available through the REST API with a production API key. The system can be reproduced with the following series of API calls:
- POST /mem/create (create new empty Memory)
- For each source segment in the test set:
- GET /tr (translate test segment)
12/28/16
Lilt adapted
The Lilt adaptive system available through the REST API with a production API key. The system simulates a scenario in which an extant corpus of source/target data is added for training prior to translating the test set. The system can be reproduced with the following series of API calls:
- POST /mem/create (create new empty Memory)
- For each source/target pair in the TM data:
- POST /mem (update Memory with source/target pair)
- For each source segment in the test set:
- GET /tr (translate test segment)
01/06/2017
Lilt Interactive
The Lilt interactive, adaptive system available through the REST API with a production API key. The system simulates a scenario in which an extant corpus of source/target data is added for training prior to translating the test set. To simulate feedback from a human translator, each reference translation for each source sentence in the test set is added to the Memory after decoding. The system can be reproduced with the following series of API calls:
- POST /mem/create (create new empty Memory)
- For each source/target pair in the TM data:
- POST /mem (update Memory with source/target pair)
- For each source segment in the test set:
- GET /tr (translate test segment)
- POST /mem (update Memory with source/target pair)
01/04/2017
Google’s statistical phrase-based machine translation system. The system can be reproduced by querying the Translate API:
- For each source segment in the test set:
- GET https://translation.googleapis.com/language/translate/v2?model=base
12/28/2017
Google neural
Google’s neural machine translation system (GNMT). The system can be reproduced by querying the Premium API:
- For each source segment in the test set:
- GET https://translation.googleapis.com/language/translate/v2?model=nmt
12/28/2016
Microsoft
Microsoft’s baseline statistical machine translation system. The system can be reproduced by querying the Text Translation API:
- For each source segment in the test set:
- GET /Translate
12/28/2016
Microsoft adapted
Microsoft’s statistical machine translation system. The system simulates a scenario in which an extant corpus of source/target data is added for training prior to translating the test set. We first create a new general category project on Microsoft Translator Hub, then a new system within that project and upload the translation memory as training data. We do not provide any tuning or test data so that they are selected automatically. We let the training process complete and then deploy the system (e.g., with category id CATEGORY_ID). We then decode the test set by querying the Text Translation API, passing the specifier of the deployed system as category id:
- For each source segment in the test set:
- GET /Translate?category=CATEGORY_ID
12/30/2016 (after the migration of Microsoft Translator to the Azure portal)
Microsoft neural
Microsoft’s neural machine translation system. The system can be reproduced by querying the Text Translation API with the “generalnn” category id:
- For each source segment in the test set:
- GET /Translate?category=generalnn
Systran neural
Systran’s “Pure Neural” neural machine translation system. The system can be reproduced through the demo website. We manually copy-and-pasted the source into the website in batches of no more than 2000 characters. We verified that line breaks were respected and that batching had no impact on the translation result. This comprised considerable manual effort and was performed over the course of several days.
Date(s): en-de: 2016–12–29–2016–12–30; en-fr: 2016–12–30–2017–01–02
SDL
SDL’s Language Cloud machine translation system. The system can be reproduced through a pre-translation batch task in Trados Studio 2017.
01/03/2017
SDL adapted
SDL’s “AdaptiveMT” machine translation system, which is accessed through Trados Studio 2017. The system can be reproduced by first creating a new AdaptiveMT engine specific to a new project and pre-translate the test set. The new project is initialized with the TM data. We assume that the local TM data is propagated to the AdaptiveMT engine for online retraining. The pre-translation batch task is used to generate translations for all non-exact matches. Adaptation is performed on the TM content. In the adaptation-based experiments, we did not confirm each segment with a reference translation due to the amount of manual work that would have been needed in Trados Studio 2017.
The Lilt adapted, Microsoft adapted and SDL adapted systems are most comparable as they were adapted in batch mode, namely by uploading all TM data, allowing training to complete, and then decoding the test set. Of course, other essential yet non user-modifiable factors such as the baseline corpora, optimization procedures, and optimization criteria can and probably do differ.
Test Corpora
We defined four requirements for the test corpus:
- It is representative of typical paid translation work
- It is not used in the training data for any of the competing translation systems
- The reference translations were not produced by post-editing from one of the competing machine translation solutions
- It is large enough to permit model adaptation
Since all systems in the evaluation are commercial production systems, we could neither enforce a common data condition nor ensure the exclusion of test data from the baseline corpora as in requirement (2). Nevertheless, in practice it is relatively easy to detect the inclusion of test data in a system’s training corpus via the following procedure:
- Select a candidate test dataset
- Decode test set with all unadapted systems and score with BLEU
- Identify systems that deviate significantly from the mean (in our case, by two standard deviations)
- If a system exists in (3):
- Sample a subset of sentences and compare the MT output to the references.
- If reference translations are present,
- Eliminate the candidate test dataset and go to (1)
- Accept the candidate test dataset
Starting in November 2016, we evaluated the eight public datasets described in the Appendix with respect to these criteria. The ninth corpus that we tried was SwissAdmin, which both satisfied our requirements and passed our data selection procedure.
SwissAdmin is a multilingual collection of press releases from the Swiss government from 1997–2013. We used the most recent press releases. We split the data chronologically, reserving the last 1300 segments of the 2013 articles as English-German test data, and the last 1320 segments as English-French test set. Chronological splits are standard in MT research to account for changes in language use over time. The test sets were additionally filtered to remove a single segment that contained more than 200 tokens. The remainder of articles from 2011 to 2013 were reserved as in-domain data for system adaptation.
SwissAdminen-deen-frTMtestTMtest#segments18,6211,29918,1631,319#words548,435 / 482,69239,196 / 34,797543,815 / 600,58540,139 / 44,874
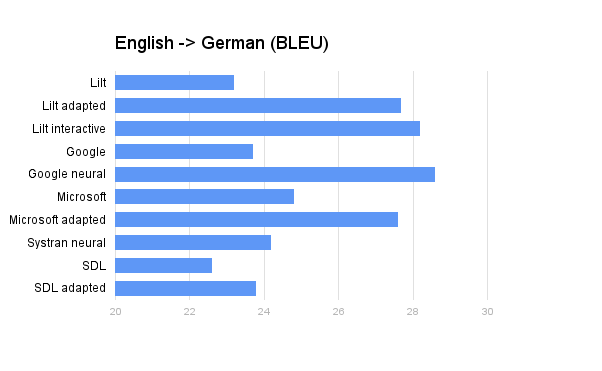
Results
(Updated with Microsoft neural MT)


Appendix: Candidate Datasets
The following datasets were evaluated and rejected according to the procedure specified in the Test Corpora section:
- JRC-Acquis
- PANACEA English-French
- IULA Spanish-English Technical Corpus
- MuchMore Springer Bilingual Corpus
- WMT Biomedical task
- Autodesk Post-editing Corpus
- PatTR
- Travel domain data (from booking.com and elsewhere) crawled by Lilt
1 We were unable to produce an SDL interactive system comparable to Lilt interactive. We first tried confirming reference translations in Trados Studio. However, we found that that model updates often requires a minute or more of processing. Suppose that pasting the reference into the UI requires 15 seconds, and the model update requires 60 seconds. For en-de, 1299 * 75 / 3600 = 27.1 hours would have been required to translate the test set. We then attempted to write interface macros to automate the translation and confirmation of segments in the UI, but the variability of the model updates, and other UI factors such as scrolling prevented successful automation of the process. The absence of a translation API prevented crowd completion of the task with Amazon Mechanical Turk.