Neural MT systems generate translations one word at a time. They can still generate fluid translations because they choose each word based on all of the words generated so far. Typically, these systems are just trained to generate the next word correctly, based on all previous words. One systematic problem with this word-by-word approach to training and translating is that the translations are often too short and omit important content. In the paper Neural Machine Translation with Reconstruction, the authors describe a clever new way to train and translate. During training, their system is encouraged not only to generate each next word correctly but also to correctly generate the original source sentence based on the translation that was generated. In this way, the model is rewarded for generating a translation that is sufficient to describe all of the content in the original source.
The most popular way of finding a translation for a source sentence with a neural sequence-to-sequence model is a simple beam search. The target sentence is predicted one word at a time and after each prediction, a fixed number of possibilities (typically between 4 and 10) is retained for further exploration. This strategy can be suboptimal as these local hard decisions do not take the remainder of the translation into account and can not be reverted later on.
This article describes the technology behind Lilt’s interactive translation suggestions. The details were first published in an academic conference paper, Models and Inference for Prefix-Constrained Machine Translation. Machine translation systems can translate whole sentences or documents, but they can also be used to finish translations that were started by a person — a form of autocomplete at the sentence level. In the computational linguistics literature, predicting the rest of a sentence is called prefix-constrainedmachine translation. The prefix of a sentence is the portion authored by a translator. A suffix is suggested by the machine to complete the translation. These suggestions are proposed interactively to translators after each word they type. Translators can accept all or part of the proposed suffix with a single keystroke, saving time by automating the most predictable parts of the translation process.
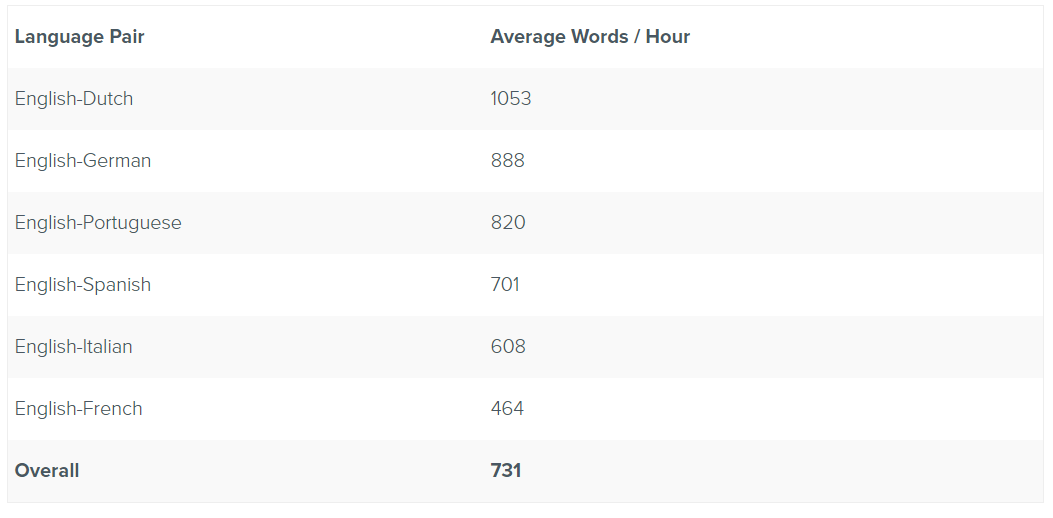
Abstract: We compare human translation performance in Lilt to SDL Trados, a widely used computer-aided translation tool. Lilt generates suggestions via an adaptive machine translation system, whereas SDL Trados relies primarily on translation memory. Five in-house English–French translators worked with each tool for an hour. Client data for two genres was translated. For user interface data, subjects in Lilt translated 21.9% faster. The top throughput in Lilt was 39.5% higher than the top rate in Trados. This subject also achieved the highest throughput in the experiment: 1,367 source words per hour. For a hotel chain data set, subjects in Lilt were 13.6% faster on average. Final translation quality is comparable in the two tools.
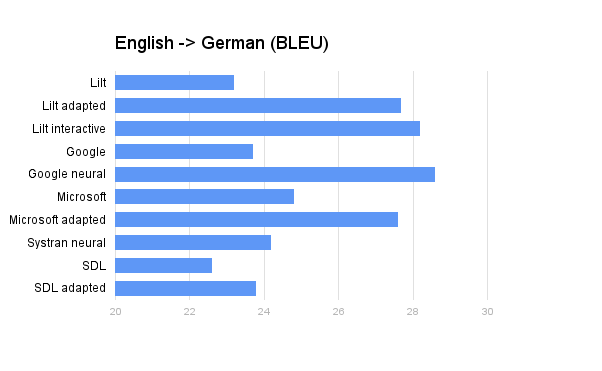
This post is an addendum to our original post on 1/10/2017 entitled 2017 Machine Translation Quality Evaluation. Experimental Design We evaluate all machine translation systems for English-French and English-German. We report case-insensitive BLEU-4 [2], which is computed by the mteval scoring script from the Stanford University open source toolkit Phrasal. NIST tokenization was applied to both the system outputs and the reference translations.
The language services industry offers an intimidating array of machine translation options. To help you separate the truly innovative from the middle-dwellers, your pals here at Lilt set out to provide reproducible and unbiased evaluations of these options using public data sets and a rigorous methodology. This evaluation is intended to assess machine translation not only in terms of baseline translation quality, but also regarding the quality of domain adapted systems where available. Domain adaptation and neural networks are the two most exciting recent developments in commercially available machine translation. We evaluate the relative impact of both of these technologies for the following commercial systems:
Guest post by Jost Zetzsche, originally published in Issue 16–12–268 of The Tool Box Journal. Some of you know that I’ve been very interested in morphology. No, let me put that differently: I’ve been very frustrated that the translation environment tools we use don’t offer morphology. There are some exceptions — such as SmartCat, Star Transit, Across, and OmegaT — that offer some morphology support. But all of them are limited to a small number of languages, and any effort to expand these would require painful and manual coding. Other tools, such as memoQ, have decided that they’re better off with fuzzy recognition than specific morphological language rules, but that clearly is not the best possible answer either. So, what is the problem? And what is morphology in translation environment tools about in the first place?
Originally published on Kirti Vashee’s blog eMpTy Pages. Lilt is an interactive and adaptive computer-aided translation tool that integrates machine translation, translation memories, and termbases into one interface that learns from translators. Using Lilt is an entirely different experience from post-editing machine translations — an experience that our users love, and one that yields substantial productivity gains without compromising quality. The first step toward using this new kind of tool is to understand how interactive and adaptive machine assistance is different from conventional MT, and how these technologies relate to exciting new developments in neural MT and deep learning. Interactive MT doesn’t just translate each segment once and leave the translator to clean up the mess. Instead, each word that the translator types into the Lilt environment is integrated into a new automatic translation suggestion in real time. While text messaging apps autocomplete words, interactive MT autocompletes whole sentences. Interactive MT actually improves translation quality. In conventional MT post-editing, the computer knows what segment will be translated, but doesn’t know anything about the phrasing decisions that a translator will make. Interactive translations are more accurate because they can observe what the translator has typed so far and update their suggestions based on all available information.





.jpeg)