
Lilt investit sans relâche dans la conception de ses systèmes et la configuration de ses déploiements en vue de rendre sa traduction automatique rapide et hautement disponible. Dans cet article, nous vous expliquons comment nous avons restructuré le code utilisé pour traduire des segments par lots afin de mieux synchroniser les ressources de GPU disponibles.
Un système qui a atteint ses limites
Lorsque nous avons lancé notre traduction automatique auprès de nos clients autonomes, la traduction se faisait à l'aide de tâches Kubernetes (k8s). Toute requête de traduction soumise par le biais de notre point de terminaison /translate était traitée comme une tâche k8s distincte.
L'approche fonctionnait très bien. Dans une certaine mesure, nous disposions d'une solution élégante et épurée. Cependant, nous nous sommes rapidement rendu compte que, pour nos clients qui devaient traiter de gros volumes, les performances n'étaient pas à la hauteur de leurs espérances au moment de faire appel au point de terminaison/translate en masse.
De nouveaux nœuds étaient provisionnés de manière dynamique dans notre cluster Google Cloud Platform (qui héberge lilt.com) lorsqu'aucun n'était disponible. Ce processus pouvait prendre plusieurs minutes, notamment pour les nœuds GPU ayant une disponibilité réduite.
Lorsqu'une tâche k8s était programmée au niveau d'un nouveau nœud, l'image Docker de l'application (plus de 5 Go) devait être téléchargée sur le nœud. Ce processus pouvait prendre plus de 60 secondes, une surcharge considérable pour un point de terminaison API comme /translate dont les clients s'attendent à ce qu'il génère des résultats plus rapides. Étant donné que chaque tâche traitait une seule requête à la fois avant de se fermer, il fallait démarrer et arrêter les nœuds fréquemment, ce qui générait des frais de surcharge plus importants.
En outre, les frais de surcharge ne se limitaient pas à l'approvisionnement en VM et à la superposition de nœuds k8s.
Une fois qu'une tâche k8s commençait, nous subissions une surcharge additionnelle de 9 à 14 secondes environ, le temps que TensorFlow charge certaines bibliothèques au démarrage des conteneurs et que Python s'initialise.
En outre, ces tâches ne réutilisaient pas les objets précédemment chargés, comme les services de traitement de texte ou les fichiers modèles spécifiques à Lilt, et le chargement de chacun d'eux pouvait prendre plusieurs secondes, tout au moins.
Enfin, plus important encore : la traduction de lots composés de multiples petits documents comme des tâches distinctes était inefficace et ralentissait le débit du système dans son ensemble. Par exemple, l'ancien système prenait plusieurs minutes pour ne traiter qu'une centaine de petits documents en utilisant 8 processeurs graphiques en parallèle ! En eux-mêmes, les modèles de traduction automatique étaient rapides. Une fois que nous concaténions le contenu de ces petits documents dans un fichier et l'exécutions sur un GPU, le processus ne prenait que quelques secondes.
Stratégie d'amélioration
Pour résumer, nous pouvions facilement profiter de certains avantages en re-concevant le système, mais nous faisions également face à des problèmes plus difficiles à résoudre, ainsi qu'à des limites inhérentes au système et aux logiciels difficiles à lever, compte tenu des contraintes de temps qui étaient les nôtres.
- Utiliser des nœuds de calcul à longue durée qui ne se ferment pas après le traitement d'une seule requête. Ils pourront ainsi réutiliser les objets précédemment chargés et amortir le temps important nécessaire au démarrage.
- Utiliser des déploiements Kubernetes pour les nœuds de calcul au lieu des tâches. Le nombre de nœuds de calcul pourra ainsi être ajusté de manière dynamique et indiquer à Kubernetes de changer le nombre d'instances dupliquées. Ce processus est avantageux lorsque vous lancez une nouvelle version, souvent plusieurs fois par semaine. Le nombre d'anciens nœuds de calcul sera réduit, alors que le nombre de nouveaux sera automatiquement augmenté. En complément, notre système de surveillance, Prometheus, est en mesure de récupérer des métriques provenant directement des nœuds de calcul.
- Développer un service Watchdog personnalisé, qui pourra détecter les défaillances et les délais liés aux nœuds de calcul.
- Si de multiples petits documents sont envoyés en traduction par lot, les mettre en lot et les traiter ensemble (non couvert dans cet article).
Architecture repensée
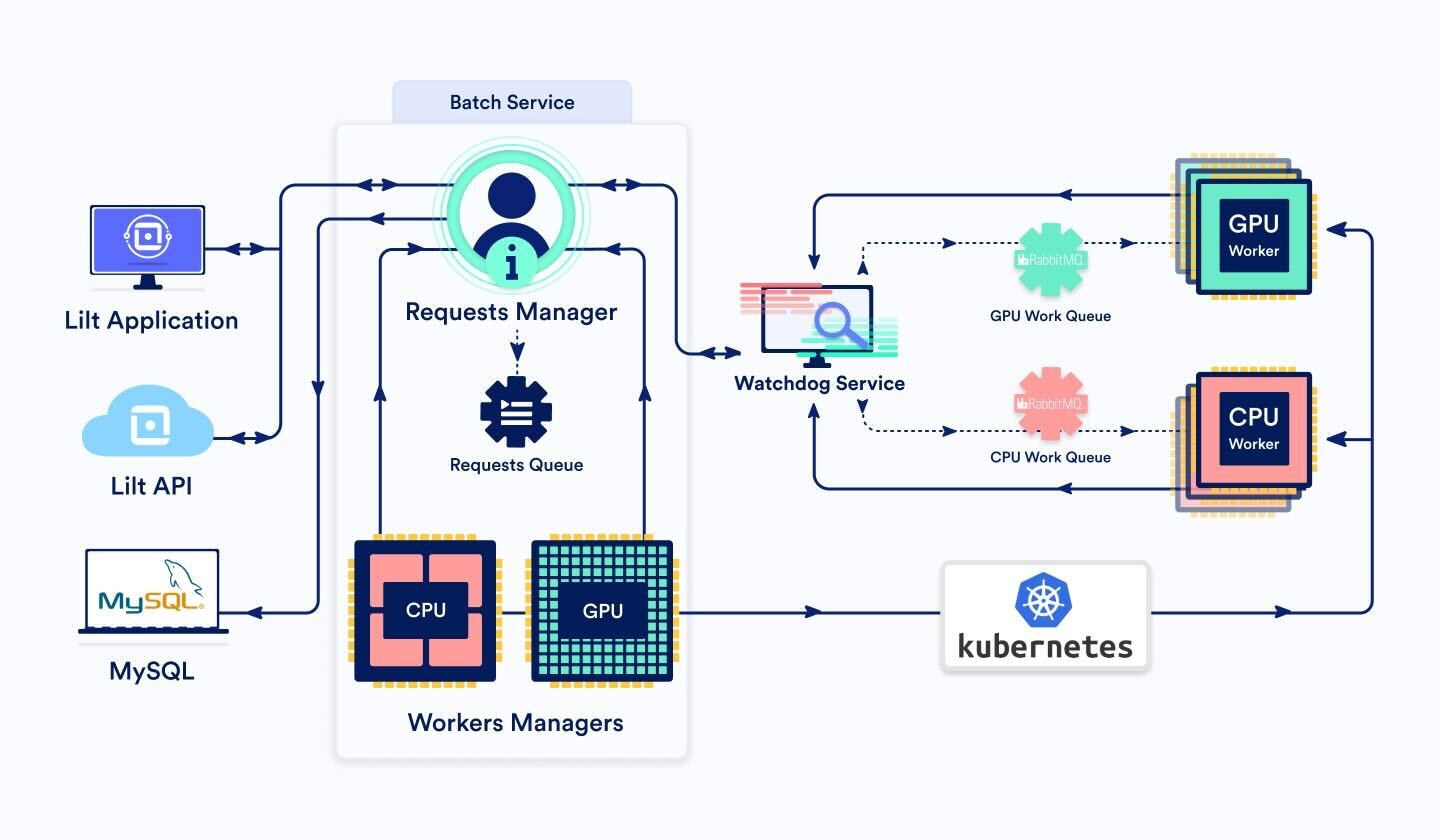
BatchService
Ce service comporte trois composantes principales :
BatchRequestsManager et BatchRequestsQueue
Lorsqu'une requête groupée entre via l'API ou l'interface de Lilt, elle est acheminée au gestionnaire BatchRequestsManager. En fonction du nombre de segments à traiter, ce dernier détermine si le traitement de la requête doit être effectué par un nœud de calcul du GPU ou du CPU. En règle générale, pour moins de 3 000 segments, nous utilisons le CPU. Sinon, nous optons pour le GPU.
Le gestionnaire génère un ID pour la tâche et rédige les détails de cette dernière dans la base de données. Nous pouvons ainsi suivre la requête tout au long de sa durée de vie.
La tâche est ensuite ajoutée à BatchRequestsQueue, une classe qui gère la priorité et l'ordre des requêtes en cours.
Puisque c'est le gestionnaire qui se charge d'enregistrer l'état de la tâche dans la base de données, au démarrage, son lancement peut se faire avec toutes les tâches en file d'attente et en cours.
Si le nombre de tâches en cours de traitement par les nœuds de calcul est inférieur au nombre maximal de nœuds de calcul (c'est-à-dire qu'il est possible de prendre plus de travail), le service Watchdog envoie un message à la file d'attente des messages du nœud de calcul par lot (ou « BatchWorker ») concerné (CPU ou GPU). BatchService actualise le statut de la tâche dans la base de données, qui affichera « submitted ».
Une fois la tâche terminée, le gestionnaire nettoie les fichiers temporaires et supprime la tâche de la base de données.
BatchWorkersManager
Au niveau de nos services de production, le nombre de nœuds et de nœuds de calcul est variable. Toutefois, ils ne s'adaptent pas parfaitement à la charge. Si les ressources du cluster sont trop faibles, le temps de démarrage du nouveau nœud de calcul retarde le traitement des requêtes groupées. Si les ressources du cluster sont trop importantes, nous perdons de l'argent à cause des nœuds de calcul non utilisés.
Il nous faut donc une classe BatchWorkersManager qui nous permet d'ajuster le nombre de nœuds de calcul disponibles. Pour ce faire, nous appelons l'API Kubernetes pour configurer le nombre d'instances dupliquées de pods de nœuds de calcul. Nous disposons de deux instances de BatchWorkersManager, une pour le CPU, une autre pour les nœuds de calcul du GPU.
La logique est la suivante :
- Appeler BatchRequestsManager pour obtenir le nombre de tâches actuellement traitées par les nœuds de calcul.
- À ce chiffre, ajouter le nombre de nœuds de calcul en attente pour permettre un lissage des ressources.
- Ajuster ce chiffre pour qu'il soit compris entre les minimum et maximum stricts de clusters.
- S'il est possible de réduire le nombre d'instances dupliquées, tout d'abord, attendre quelques minutes avant de vérifier à nouveau si une réduction est encore souhaitable. Cela permet de fluidifier l'approvisionnement en ressources.
BatchWorker (nombre dynamique de pods)
Dans ce système, les BatchWorkers représentent la plus petite unité de ressources. Lorsqu'un BatchWorker récupère un message de la file d'attente de messages de la tâche, il commence à traiter la requête et envoie périodiquement un message de pulsation au service Watchdog pour éviter que ce dernier ne l'arrête.
Il est impossible de déterminer la durée du traitement d'une requête puisqu'elle dépend du nombre de segments à traduire, qui peut être très variable. Une fois ce processus terminé, le BatchWorker utilise le service Watchdog pour envoyer un message indiquant que la tâche est terminée au BatchService. Il accuse réception de la requête dans rabbitmq et récupère le prochain message de la file d'attente.
Notons que, lorsque Kubernetes essaie d'arrêter des nœuds de calcul, par exemple, après le lancement d'une nouvelle image ou la réduction du nombre d'instances dupliquées, il permet un délai de latence au nœud de calcul pour qu'il puisse terminer le traitement de ses requêtes. Nous avons configuré ce paramètre « terminationGracePeriodSeconds » sur une valeur élevée, car nous ne pouvons pas demander à Kubernetes d'arrêter un nœud de calcul en particulier lors d'un scaling à la baisse. Nous permettons ainsi à chaque nœud de calcul de finaliser le traitement des requêtes existantes. Une fois le processus de traitement terminé, il s'arrête.
Service Watchdog
Le service Watchdog est là pour garder un œil sur les requêtes asynchrones et détecter toute panne ou défaillance éventuelle.
Si le service A (par ex. : le Batch Service) souhaite envoyer une requête au service B (par ex. : un BatchWorker), mais ne souhaite pas attendre qu'une réponse synchrone arrive (car la réponse devrait être longue, par exemple), il peut envoyer la requête par le biais du service Watchdog, en lui indiquant quel est le service ciblé. Le service Watchdog transmettra la requête au service cible B. Le Service B doit alors régulièrement envoyer des messages de pulsation au service Watchdog pour indiquer que la requête est toujours active et en cours de traitement. Une fois que le service B termine de traiter la requête, il renvoie une réponse au service Watchdog. Ensuite, le service Watchdog transmet la réponse au service d'origine A.
Si, pendant un certain temps, le service Watchdog ne reçoit pas de messages de pulsation concernant une requête, il la considérera comme en échec et enverra un message d'échec au service A d'origine.
Étant donné que nous prenons en charge des requêtes de taille variable (car le nombre de segments de l'appel d'API peut considérablement varier, tout comme la nature des données du document), il était logique d'adopter un traitement asynchrone et d'utiliser le service Watchdog.
Autres améliorations
Nous pouvons encore augmenter notre débit de traduction automatique ! Voici quelques-unes des idées que nous envisageons pour la phase à venir :
-Trouver un moyen d'indiquer à Kubernetes quels nœuds de calcul doivent être arrêtés lorsqu'il réduit le nombre d'instances dupliquées. Par exemple, en sélectionnant le nombre de nœuds de calcul qui ne traitent pas activement une requête ou ceux avec les plus petits caches de modèles. À ce jour, il semble qu'il n'existe aucune manière d'y arriver (voir https://github.com/kubernetes/kubernetes/issues/45509).
-Diviser les documents volumineux en plusieurs parties et utiliser plusieurs nœuds de calcul pour les traiter en parallèle.
-Renvoyer des résultats partiels pendant le traitement, de sorte que les clients n'aient pas à attendre que le document soit terminé.
-Lorsqu'une requête est distribuée aux nœuds de calcul, trouver un moyen d'accorder la priorité à un nœud de calcul déjà téléchargé et chargé avec les modèles et les actifs nécessaires au traitement de la paire de langues de la requête. Cela peut réduire le temps nécessaire au traitement des requêtes.