
Dans cet article, vous découvrirez de quelle manière Lilt transforme une énorme pile de données et d'équations mathématiques en traductions utilisant un langage naturel. Même si les modèles de traduction automatique donnent parfois l'impression de relever de la magie, ici, nous allons vous laisser jeter un œil dans les coulisses !
Collecte des données
Entraîner un modèle de traduction automatique (ou MT, pour Machine Translation), c'est un peu comme cuisiner à l'aide d'une recette. Pour que votre plat soit bon, il vous faut non seulement suivre les étapes, mais également utiliser des ingrédients frais.
Lilt utilise des sources de données ouvertes ou payantes pour obtenir des données de texte parallèles, le composant clé des modèles de traduction automatique.
Les sources ouvertes sont des sources de données de textes parallèles libres, gratuites et vérifiées, et sont généralement disponibles sous une licence CC-BY ou CC-BY-SA. Nous utilisons notamment Opus, Paracrawl et CCMatrix.
Les sources payantes sont mises à disposition sous une licence CC-NC. Elles peuvent être utilisées uniquement à des fins non commerciales et de recherche. Nous devons payer des frais pour pouvoir les utiliser dans nos modèles. Citons, par exemple, la source WIPO COPPA V2.
Si l'on parle de taille des données -- plus il y en a, mieux c'est. Généralement, plus les données sont nombreuses, meilleure est la qualité des modèles de traduction automatique. Jusqu'à ce jour, nous avons collecté 3,8 milliards de segments sur 76 paires de langues.
Préparation des données
Chaque élément de données que nous obtenons à partir des sources mentionnées plus haut est traité avec rigueur. Avant même de commencer l'entraînement, la préparation des données nécessite un travail herculéen. Voici comment nous opérons !
Nettoyage et validation
Nous procédons à un nettoyage basique basé sur des syntaxes en utilisant les étapes suivantes :
- Suppression de toutes les phrases vides
- Suppression des phrases contenant uniquement de la ponctuation
- Validation des fichiers des langues source et cible qui doivent contenir le même nombre de segments (sinon, la source est rejetée)
Versionnage des données
Nous versionnons nos données avec DVC. Cela nous permet de combiner les fichiers source et cible et tout fichier de suivi interne supplémentaire en une seule unité. L'unité unique prend la forme d'un fichier .dvc et est rattachée à notre Github pour suivre toutes les sources de données que nous utilisons.
Normalisation des segments
Afin d'assurer la cohérence de tous les segments, nous suivons les étapes suivantes :
- Normalisation de l'Unicode : conversion d'un texte, comme en Unicode ou en HTML, en un texte lisible par l'humain. Par exemple : Broken text… it’s flubberific! sera converti en Broken text... it's flubberific!
- Normalisation des espaces insécables : pour les langues comme le français, certaines règles strictes s'appliquent sur la position des espaces insécables. Cette étape consiste à ajouter les espaces nécessaires, s'ils ne sont pas déjà présents.
Filtrage
Premièrement, nous supprimons les segments potentiellement problématiques d'un corpus, au niveau du segment ou d'une paire de segments. C'est ce que l'on nomme un filtrage individuel.
- Script : il est juste de supposer que, si un segment en ja (japonais) contient un jeton/une phrase en ta (tamil), il ne peut pas être utilisé pendant l'entraînement. Nous appliquons des règles pour les scripts inefficaces au moment de leur intégration dans un autre script et supprimons ces segments.
- Code de la langue : nous utilisons le paquet python cld3 pour identifier la langue d'un segment. Si elle ne correspond pas à la langue du corpus, le segment est rejeté.
- Exclusions des modèles : nous excluons les segments qui correspondent à des expressions régulières et identifient des modèles problématiques, par exemple, « http:// » pour les URL.
- Longueur des segments : nous excluons tout segment de plus de 300 mots (configurable par langue).
- Erreurs de chiffres : nous excluons toute paire de segments qui utilisent le même système numérique, mais contiennent des chiffres différents dans les segments source et cible.
- Ratio de longueur : nous excluons tout segment pour lequel le segment source ou cible est inhabituellement long ou court pour la paire de segments, après comparaison avec un seuil calculé sur l'intégralité du corpus.
- Distance de modification : nous excluons tout segment dont les segments source et cible sont identiques ou similaires. En effet, cela peut indiquer une mauvaise traduction. Nous vérifions la distance de modification entre les segments source et cible par rapport à un seuil minimum de 0,2.
Enrichissement des données
Si des données peu familières ou sous-représentées sont présentées aux modèles de traduction automatique, ils risquent de produire des « hallucinations », c'est-à-dire des traductions totalement détachées du texte source d'origine. Afin de résoudre ce problème, nous générons artificiellement des exemples de phrases parallèles (enrichissement). L'entraînement réalisé avec des exemples enrichis permet d'améliorer la robustesse et la résilience du modèle à l'égard de ces données. C'est ce qui nous permet de produire des traductions efficaces pour nos clients dans une grande variété de domaines. Nous enrichissons les paires de segments existantes de différentes manières :
- Multi-segmentation : nous concaténons jusqu'à 5 segments consécutifs pour former un seul et unique segment long.
- Mise en majuscule : nous modifions la casse des segments sélectionnés en fonction des schémas de mise en majuscule MAJUSCULE et Premier Caractère En Majuscule.
- Termes non traduisibles : nous introduisons les mots à ne pas traduire qu'utilisent nos clients en détectant les jetons/phrases courants dans les segments source et cible et en les entourant des caractères ${ et }.
Codage par paire d'octets (BPE)
Dans un grand corpus, la quantité de vocabulaire peut être énorme et de nombreux mots sont peu utilisés. Nous procédons à un codage par paire d'octets (BPE) sur les mots pour les diviser en petits morceaux (par exemple, mangerons peut devenir manger et ons). Nous pouvons ainsi corriger la taille du vocabulaire et, par extension, le modèle de traduction automatique et, donc, les ressources nécessaires pour entraîner le modèle.
Grâce au BPE, nous pouvons diviser les jetons en morceaux de mots communs et ainsi traduire des segments avec des jetons qui n'apparaissent pas dans le corpus d'entraînement, ce qui est courant dans les langues riches sur le plan morphologique (comme les langues romanes et slaves).
Entraînement des modèles de traduction automatique
Depuis que l'architecture« Transformer » est apparue, c'est sur elle que nous avons basé nos modèles de traduction de production.
Avant de passer aux spécificités de ce modèle de transformateur, permettez une digression rapide sur un concept appelé espace d'intégration ou espace de représentation continue. Chaque point de ce grand espace représente le sens d'une phrase. Deux phrases similaires, qui ont la même signification, auront des représentations proches l'une de l'autre. Vous pouvez deviner comment ce concept s'intègre dans la conception d'un modèle de traduction automatique. Il nous suffit de concevoir deux composantes :
Encodeur : il prend une phrase source et la transforme en une représentation de l'espace d'intégration.
Décodeur : il prend la représentation de l'espace d'intégration et la convertit en une phrase dans la langue cible.
L'encodeur et le décodeur forment ensemble un modèle de traduction automatique pour une paire de langues donnée. Le nom générique Sequence-to-sequence (seq2seq) est utilisé pour les modèles utilisant cette architecture de codeur-décodeur, le modèle Transformer étant largement considéré comme le plus performant.
Voici à quoi ressemble un modèle Transformer :
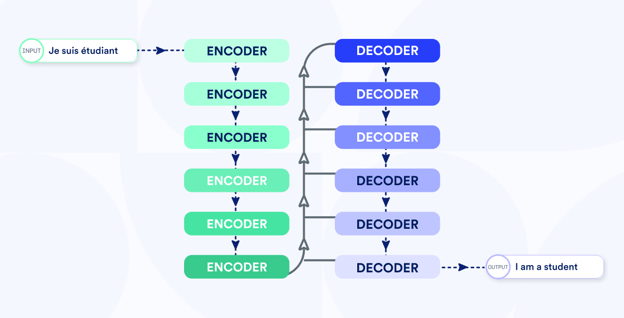
Étant donné l'architecture, nous devons choisir la taille du modèle. La taille du modèle est déterminée par le nombre de paramètres. Elle est comparable à la capacité d'un hôtel. Les informations extraites des corpus en entraînement correspondent au nombre de personnes réellement présentes dans un hôtel.
Nous voulons atteindre une utilisation maximale. Pour cela, nous utilisons le nombre de phrases dans les corpus parallèles obtenus de la section Préparation des données pour déterminer la taille du modèle la plus adaptée à une paire de langues donnée :
- Petit modèle lorsqu'il y a moins de paires de phrases parallèles disponibles, par exemple Anglais -> Hindi
- Grand modèle lorsqu'il y a une abondance de paires de phrases parallèles disponibles, par exemple Anglais -> Allemand
Ensuite, nous entraînons le modèle. Nous pourrions entrer dans des détails plus spécifiques dans un article de blog à venir. Mais, pour résumer, nous déployons beaucoup de nœuds de calcul de haute performance, nous entraînons le modèle avec les données d'entraînement générées à la section Préparation des données et, pour finir, nous analysons les performances du modèle en utilisant des ensembles de tests préparés par des organisations comme WMT, TED et des groupes universitaires comme LTI.
Pour noter les modèles, nous utilisons des mesures automatiques comme le score BLEU, qui répond à des questions telles que « Comment évaluer objectivement ce qu'est un bon modèle de l'anglais au français ? ».
Après avoir passé l'épreuve du feu, nous installons le modèle sur nos serveurs de production et nos traducteurs peuvent commencer à l'utiliser immédiatement !