
Vous savez peut-être déjà comment les machines traduisent entre deux langues humaines ; sinon, consultez notre blog d'introduction sur le sujet. Ce qui suit est une exploration avancée dans un aspect de la traduction automatique : le transfert de format.
La traduction professionnelle est plus complexe que la simple traduction de texte brut. La traduction doit préserver la mise en forme, comme les caractères gras, l'italique et le balisage du mieux possible.
Dans cet article, nous décrivons comment Lilt conserve la mise en forme dans la traduction. Nous aborderons :
- la représentation des balises
- l'alignement des mots et l'attention
- la visualisation des fonctionnalités
- la tolérance aux erreurs et les séquences de mots multiples
La représentation des balises
Lors de la localisation d'un document dans une autre langue, un traducteur doit non seulement traduire le texte, mais aussi transférer la mise en forme. Considérez l'extrait suivant de Wikipédia :

Premier paragraphe de l'article de Wikipédia sur la traduction
Après avoir traduit le contenu de texte brut en allemand, par exemple, le traducteur doit encore transférer la mise en forme (gras, mise en italique et balisage HTML) dans le texte allemand cible. La mise en forme peut être représentée comme étant l'ouverture et la fermeture des balises qui s'étend sur une certaine plage de caractères dans les balises. Voici à quoi cela ressemble dans l'interface Lilt :
Au début, le traducteur voit le segment dans la langue source, y compris les balises de mise en forme. Le traducteur traduit le segment en interagissant avec les suggestions générées par la machine. Après avoir terminé la traduction, Lilt transfère automatiquement les balises de mise en forme dans la version du traducteur. Dans l'idéal, les balises apparaissent à des positions raisonnables dans la traduction ; sinon, le traducteur peut modifier manuellement les positions des balises par un glisser-déposer ou des raccourcis clavier.
L'alignement des mots et l'attention
Rappel : les segments sources lors de la traduction automatique sont divisés en jetons en interne, qui sont des segments de sous-mot.
Pour transférer la mise en forme, nous devons déterminer les positions des balises de mise en forme dans la traduction. Pour ce faire, il est utile de savoir quels mots dans la phrase source et la traduction correspondent les uns aux autres, un problème appelé alignement des mots. Nous pouvons plus tard utiliser ces informations pour déterminer les positions des balises de mise en forme dans la traduction.
Les réseaux neuronaux pour la traduction automatique contiennent déjà un composant appelé « attention » qui modélise les correspondances entre les jetons de la phrase source et la traduction. L'attention spécifie dans quelle mesure chaque jeton de la phrase source influence la génération d'un jeton de la traduction en tant que distribution de probabilité.
L'attention est mieux visualisée à l'aide d'une matrice avec ombrage pour indiquer l'importance. Voici un exemple de traduction de l'allemand vers l'anglais, avec les jetons en allemand sur la gauche, et ceux de la traduction en anglais en haut :
Il s'agit de la matrice d'attention moyenne extraite d'un système de traduction automatique basé sur un transformeur. Plus le point est sombre dans cette matrice, plus le jeton est important dans la production d'un certain jeton dans la traduction, c'est-à-dire plus l'attention est élevée. Par exemple, les jetons les plus importants pour générer l'anglais « _believe » sont, en allemand, « _glauben », « _nicht » et « _ ».
Nous pouvons également utiliser cette fonctionnalité pour transférer la mise en forme. Par exemple, si le mot « glauben » était en gras dans le texte d'origine, nous pourrions utiliser la matrice d'attention et sélectionner le point le plus sombre de la ligne, et mettre en gras le jeton correspondant dans la traduction. Nous voulions donc mettre en gras le mot anglais « believe ». Faire la même chose pour tous les jetons et le problème résolu ?
Pas tout à fait ! Malheureusement, la matrice d'attention ci-dessus est assez bruyante. Beaucoup d'attention est accordée au jeton de ponctuation « _ », ce qui ne reflète pas l'importance qu'un traducteur humain donnerait à ce point pour produire les mots individuels de la phrase en anglais.
L'architecture du transformateur que nous utilisons pour générer des traductions peut être divisée en un codeur et en un décodeur. Le codeur code la phrase source en un vecteur par jeton source. Le décodeur génère un jeton de la traduction de manière itérative. À chaque étape, le décodeur utilise son propre état, un autre vecteur, pour s'occuper des jetons d'encodeur les plus pertinents, combine le résultat avec son propre état et décode finalement le jeton suivant de la traduction (la publication du blog original de Google contient une visualisation de ce processus).
Mais parfois il est même possible de générer le prochain mot de la traduction sans regarder la phrase source. Pour donner un exemple, pouvez-vous deviner comment la phrase suivante se termine ? « Le pont Golden Gate est situé à San … »
Même dans ces situations, nous voulons forcer le réseau neuronal à s'occuper des représentations sources les plus pertinentes. Nous concevons donc une couche d'alignement dédiée pour forcer le réseau neuronal à prédire le jeton suivant, en se basant uniquement sur une combinaison linéaire de la représentation source. Nous utilisons l'état du décodeur pour calculer la matrice d'attention qui est utilisée pour déterminer les poids pour la combinaison linéaire. Voici la couche d'alignement dans le contexte du modèle complet du transformateur :
Au lieu de produire le jeton suivant sur la base de l'état du décodeur comme la ligne en pointillés sur la droite l'indiquait, la couche d'alignement utilise principalement les états du codeur pour prédire le jeton suivant. Cela force l'attention de la couche d'alignement à se concentrer sur le jeton source le plus important. La matrice d'attention résultante ressemble maintenant à ceci :
Nous avons réussi à nous débarrasser des valeurs d'attention élevée sur la ponctuation dans la traduction ! Les points d'attention restants sont maintenant beaucoup plus sombres, avec des cases moins « légèrement grises » partout. En fait, nous avons affiné l'attention du modèle, ce qui finalement conduit à une meilleure projection des balises et donc à un meilleur transfert de format.
La visualisation des fonctionnalités
Bien que la couche d'alignement produit une attention raisonnable que nous pouvons utiliser pour transférer la mise en forme, nous pouvons nous améliorer. Pour cela, nous allons prendre du recul et nous rappeler comment les réseaux neuronaux effectuent la reconnaissance d'image.
Les réseaux neuronaux pour la reconnaissance d'image sont formés pour prédire une étiquette, par exemple l'étiquette « chien », pour une image donnée. Dans un modèle de reconnaissance d'image formé, on peut analyser la fonction qu'un neurone spécifique représente en générant une image d'entrée de telle sorte que ce neurone active fortement.
Cette image générée active fortement un neurone qui semble important pour reconnaître les chiens :
Image optimisée pour maximiser la sortie d'un neurone dans un modèle de reconnaissance d'image. Source : distill.pub/2017/feature-visualisation/
L'image ci-dessus est créée en commençant par une image d'entrée aléatoire, et en l'optimisant par une descente de gradient avec une fonction objective pour activer un seul neurone dans le réseau.
Retournons à notre modèle de traduction : pensez à la matrice d'attention précédemment mentionnée comme à une image avec des niveaux de gris. Rappelez-vous que chaque jeton de sortie du réseau de traduction correspond à un neurone individuel dans la couche de sortie du réseau neuronal. Étant donné que nous connaissons la traduction dans laquelle nous allons finalement transférer des balises de mise en forme, nous pouvons optimiser l'image d'attention vers une activation élevée des neurones de sortie correspondant à la traduction souhaitée.
Dans la vidéo ci-dessous, nous commençons par la matrice d'attention d'origine et l'optimisons vers une activation élevée des neurones de sortie désirés en quelques étapes de descente de gradient :
Ce processus conduit également à une matrice d'attention qui est plus utile pour mettre en forme le transfert.
La tolérance aux erreurs et les séquences de mots multiples
Jusqu'à présent, nous avons seulement examiné comment transférer une paire de balises autour d'un seul mot. Comment traiter plusieurs mots ? Nous allons examiner un exemple plus complexe et présenter un algorithme pour transférer la mise en forme qui peut corriger les incohérences dans la matrice d'attention générée.
Considérez une paire de balises qui couvre plusieurs mots, comme dans la traduction de l'anglais vers l'allemand suivante :
Pour comprendre comment transférer les balises de mise en forme dans la traduction, nous générons une matrice d'attention comme d'habitude, mais ne prenons en compte que la valeur d'attention la plus élevée pour chaque jeton cible :
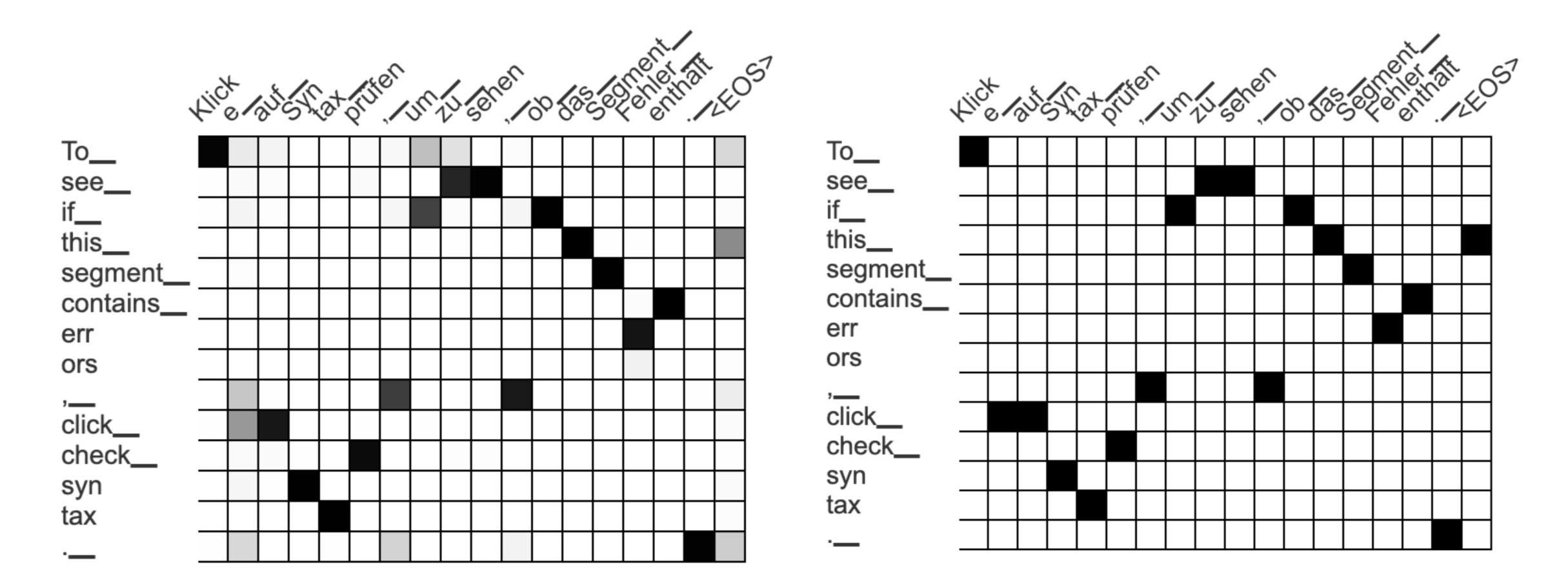
Les matrices d'attention générées automatiquement La matrice de gauche contient une distribution de probabilité pour chaque jeton de sortie allemand, la droite ne conserve que le score d'attention le plus élevé pour chaque jeton allemand.
Une façon simple de transférer une paire de balises couvrant une phrase source vers une phrase cible est la suivante :
- Regardez toutes les valeurs d'attention les plus élevées de la phrase source pour cibler les jetons
- Choisissez le jeton cible le plus à gauche et le plus à droite dans cet ensemble
- Étendez la paire de balises autour des jetons cibles les plus à gauche et les plus à droite
Dans cet exemple, nous regardons tous les scores d'attention pour la phrase « To_ see_ if_ this_ segment_ contain_ err ors », qui sont : « Klick », « um_ », « zu_ », « sehen », « ob_ », …, « Fehler_ », « enthält ». Nous sélectionnons les jetons les plus à gauche et à droite (« Klick » et « enthält ») et nous laissons la paire de balises s'étendre sur tous les jetons entre les deux :
Cela pourrait être une approche raisonnable si la matrice d'attention ne contenait jamais d'erreurs. Mais la matrice d'attention est générée automatiquement et souvent erronée ! Dans notre exemple, l'entrée incorrecte entre les jetons « To_ » et « Klick » entraîne une séquence déraisonnablement longue pour notre paire de balises.
Chez Lilt, nous avons développé un algorithme plus tolérant aux erreurs. Au lieu de sélectionner le mot cible le plus à gauche et le plus à droite comme limite pour la paire de balises, nous définissons un score pour chaque séquence possible dans la traduction. Ce score est calculé en récapitulant les comptes suivants :
- le nombre d'entrées d'attention à partir des jetons sources couverts par la paire de balises vers des jetons dans la plage cible (score dans la séquence)
- le nombre d'entrées d'attention à partir des jetons non couverts par la paire de balises vers des jetons en dehors de la plage cible (score hors séquence)
Nous calculons ce score pour chaque séquence possible dans la traduction, et sélectionnons la séquence la plus appropriée pour transférer la paire de balises. Cette approche attribue un faible score à la séquence cible déraisonnablement longue dans l'exemple précédent, car le score « hors séquence » est faible. La séquence au score le plus élevé pour notre exemple est maintenant « um zu sehen, ob das Segment Fehler enthält » avec un score de 15 :
Au-dessus de la séquence source fixe est mise en évidence en rouge et la séquence dans la traduction pour laquelle nous calculons le score est mise en évidence en jaune. Pour le score dans la séquence, nous comptons tous les carrés noirs dans la zone verte, ce qui représente l'attention entre les deux séquences. Pour le score hors séquence, nous comptons les carrés noirs dans les deux zones bleues correspondant à l'attention qui n'est associée ni à la source ni à la séquence cible. Par conséquent, nous obtenons le score de 8 (score dans la séquence) + 7 (score hors séquence) = 15.
L'algorithme de transfert de balisage a trouvé cette séquence optimale en calculant le score de toutes les séquences cibles possibles. Cela entraîne un résultat suivant plus raisonnable malgré une matrice d'attention imparfaite :
Autres publications à consulter
Cet article de blog décrit le transfert de format, mais souligne également comment les techniques d'une gamme de différents domaines peuvent améliorer le système de production de Lilt pour mieux aider les traducteurs humains. Si vous voulez vous plonger plus en profondeur dans les détails techniques de nos systèmes, lisez certaines de nos recherches :
- L'ajout d'une attention interprétable aux modèles de traduction neuronale améliore l'alignement des mots : https://arxiv.org/abs/1901.11359
- L'alignement des mots neuronaux de bout en bout surpasse Giza++ : https://aclanthology.org/2020.acl-main.146/
- Le transfert de balisage automatique bilingue : https://aclanthology.org/2021.findings-emnlp.299/