
Lilt invierte continuamente en configuraciones de diseño e implementación de sus sistemas para que su traducción automática siga siendo rápida y esté siempre disponible. Aquí describimos cómo reestructuramos el código utilizado para traducir segmentos en lotes con el fin de paralelizar mejor los recursos de GPU disponibles.
Un sistema llega a su límite
Cuando lanzamos inicialmente nuestra traducción automática para nuestros clientes autogestionados, la traducción se hacía mediante el uso de tareas de Kubernetes (k8s). Cada solicitud de traducción a través de nuestra terminal /translate se procesaba como una tarea de k8 independiente.
Si bien el enfoque sin duda funcionó, y hasta cierto punto fue una solución mínima elegante, rápidamente nos dimos cuenta de que los clientes con alta demanda de procesamiento simplemente no estaban recibiendo el desempeño que esperaban cuando llamaban a la terminal /translate masivamente.
Cuando no hay ninguno disponible, se proveen nuevos nodos dinámicamente en nuestro clúster de la plataforma Google Cloud (que aloja a lilt.com). Esto puede demorar algunos minutos, especialmente para los nodos de GPU con baja disponibilidad.
Cuando se programa una tarea de k8s en un nuevo nodo, es necesario descargar la imagen de docker de la aplicación (más de 5 GB) al nodo. Esto podría demorar más de 60 segundos, una cantidad considerable de sobrecosto para una terminal API como /translate, para la cual los clientes esperarían resultados más rápidos. Dado que cada tarea procesaba solo una solicitud y luego finalizaba, la activación y desactivación de nodos ocurría con tanta frecuencia que exacerbaba el sobrecosto.
Y el sobrecosto no terminó con el aprovisionamiento de VM y nodos k8 superpuestos.
Una vez que empezaba una tarea de k8s, incurríamos en un sobrecosto adicional de unos 9 a 14 segundos. Esto se relacionaba con el hecho de que tensorflow cargaba algunas bibliotecas en el inicio del contenedor y la inicialización de python.
Las tareas no reutilizaban los objetos previamente cargados, como los servicios de palabras específicos de Lilt, y los archivos modelo. Cargar cada uno de ellos podía demorar al menos unos segundos.
Finalmente, y lo más importante: la traducción en lote de múltiples documentos pequeños como tareas separadas era ineficiente y reducía drásticamente el rendimiento general del sistema. Por ejemplo, procesar solo un centenar de documentos diminutos en el antiguo sistema utilizando 8 GPU en paralelo demoraba varios minutos. Los modelos de traducción automática en sí eran rápidos, ya que al concatenar el contenido de esos documentos diminutos en un archivo y ejecutarlo en una GPU, el tiempo se reducía a segundos.
Estrategia de mejora
En síntesis, había muchas optimizaciones al alcance de la mano que podíamos lograr mediante el rediseño del sistema, algunas cuestiones más difíciles de resolver y algunas limitaciones de sistema y de software difíciles de resolver con nuestras limitaciones de tiempo.
- Usar trabajadores por períodos largos que no salgan después de procesar una sola solicitud. Esto les permite reutilizar los objetos previamente cargados y amortiza el prolongado tiempo de puesta en marcha.
- Usar implementaciones de Kubernetes para los trabajadores en lugar de tareas. La cantidad de trabajadores luego se puede ajustar dinámicamente diciéndole a Kubernetes que cambie la cantidad de réplicas. La ventaja es que cuando al lanzar una versión nueva, con frecuencia varias veces a la semana, se reducirá la escala de los antiguos trabajadores y se aumentará la de los trabajadores nuevos automáticamente. Como beneficio colateral, nuestro sistema de monitoreo, Prometheus, puede obtener métricas directamente de los trabajadores.
- Desarrollar un servicio de vigilancia (watchdog) personalizado para detectar y actuar en relación con desconexiones y fallas relacionadas con el trabajador.
- Si se envían múltiples documentos pequeños para su traducción conjunta en lote, se los integra en un lote y se los procesa juntos (esto no está cubierto en esta publicación).
Arquitectura rediseñada
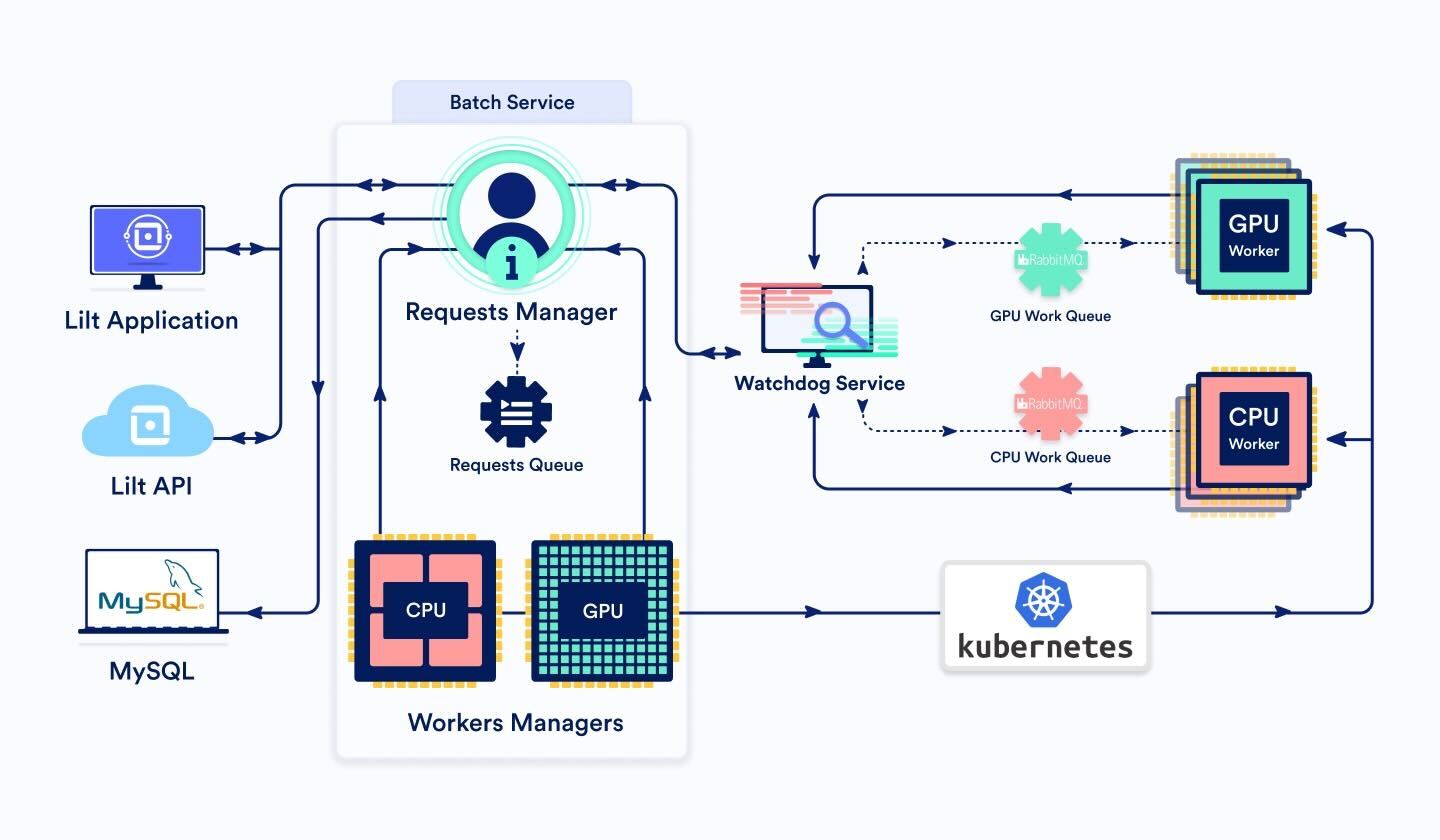
BatchService
Este servicio tiene tres componentes principales:
BatchRequestsManager y BatchRequestsQueue
Cuando una solicitud de lote entra a través de la interfaz o la API de Lilt, se la direcciona al BatchRequestsManager. Este determina si el procesamiento de la solicitud debe hacerlo un trabajador de GPU o CPU, según la cantidad de segmentos a procesar. Como regla general, cuando tenemos menos de 3000 segmentos, acudimos a la CPU, si no, a la GPU.
El administrador genera una identificación de tarea y escribe los detalles de la tarea en la base de datos (DB, por su sigla en inglés). Esto nos permite rastrear la solicitud a lo largo de su ciclo de vigencia.
Luego, la tarea se agrega a la BatchRequestsQueue, una clase que mantiene la prioridad y el orden de las solicitudes pendientes.
Dado que el administrador almacena el estado de la tarea en la DB, en la puesta en marcha, se puede inicializar con cualquier tarea en la cola o en progreso.
Si la cantidad de tareas que los trabajadores están procesando actualmente es inferior a la cantidad máxima de trabajadores (lo que significa que hay margen para tomar más trabajo), se envía un mensaje a la cola de mensajes del trabajador en lote apropiado (CPU o GPU) a través del servicio de vigilancia. BatchService actualiza el estado de la tarea en la DB a "enviado".
Cuando la tarea termina, el administrador limpia los archivos temporales y elimina la tarea de la DB.
BatchWorkersManager
En nuestros servicios de producción, la cantidad de nodos y trabajadores es variable. Sin embargo, no se escalan perfectamente según la carga. Si el clúster tiene demasiado pocos recursos, el procesamiento de solicitudes en lote se demora según el tiempo de puesta en marcha de nuevos trabajadores. Si el clúster tiene un sobreabastecimiento de recursos, desperdiciamos dinero en trabajadores ociosos.
Por lo tanto, una clase de BatchWorkersManager es necesaria para ajustar bien la cantidad de trabajadores disponibles. Esto se hace llamando a la API de Kubernetes para establecer la cantidad de réplicas de pods de trabajadores. Tenemos dos instancias de BatchWorkersManager, una para trabajadores de CPU y otra para trabajadores de GPU.
La lógica es la siguiente:
- Llamar a BatchRequestsManager para obtener la cantidad de tareas que están siendo procesadas actualmente por trabajadores.
- Incrementar esa cantidad con una cantidad de trabajadores en espera para permitir la relajación de recursos.
- Ajustar la cantidad de modo que se encuentre dentro del mínimo y máximo del clúster hard.
- Si se reduce la cantidad de réplicas, esperar X minutos primero y luego comprobar de nuevo si todavía se desea una reducción. Esto facilita el suministro de recursos.
BatchWorker (cantidad dinámica de pods)
BatchWorkers representa la unidad de recursos más pequeña de este sistema. Cuando un BatchWorker recibe un mensaje de la cola de mensajes de trabajo, comienza a procesar la solicitud y periódicamente envía un mensaje de señal operativa al servicio de vigilancia para asegurarse de que este servicio no lo desconecte.
El procesamiento de una solicitud puede demorar un tiempo ilimitado seg la cantidad de segmentos que necesiten traducción, algo que puede variar enormemente. Cuando está listo, BatchWorker envía un mensaje a través del servicio de vigilancia a BatchService indicando que la tarea ha sido completada. Este acusa recibo de la solicitud en rabbitmq y procede a buscar el próximo mensaje de la cola.
Ten presente que cuando Kubernetes intenta suspender trabajadores, por ejemplo, después del lanzamiento de una nueva imagen o de la reducción de la cantidad de réplicas, le da al trabajador un período de gracia para terminar de procesar sus solicitudes. Configuramos este parámetro, terminationGracePeriodSeconds, con un valor alto, dado que no podemos pedirle a Kubernetes que suspenda un trabajador en particular al reducir la escala. Por lo tanto, les damos a los trabajadores suspendidos la posibilidad de terminar de procesar las solicitudes existentes. Cuando el trabajador termina de procesar solicitudes, queda suspendido.
Servicio de vigilancia (Watchdog)
El servicio de vigilancia controla las solicitudes asíncronas mediante la detección de errores y fallos.
Si el servicio A (por ej., Batch Service) quiere enviar una solicitud al servicio B (por ej., un Batch Worker), pero no quiere esperar sincrónicamente una respuesta (por ej., porque se prevé que la respuesta demorará mucho tiempo), puede enviar la solicitud a través del servicio de vigilancia, al hacerle saber al servicio de vigilancia cuál es el servicio objetivo. El servicio de vigilancia remitirá la solicitud al servicio objetivo B. El servicio B luego debe enviar mensajes de señal operativa periódicamente al servicio de vigilancia para indicar que la solicitud sigue activa y en proceso. Cuando el servicio B termina de procesar la solicitud, envía una respuesta nuevamente al servicio de vigilancia. El servicio de vigilancia luego remitirá la respuesta al servicio originador A.
Si el servicio de vigilancia no recibe mensajes de señal operativa para una solicitud luego de cierto tiempo, considerará que la solicitud falló, y enviará un mensaje de fallo al servicio originador A.
Debido a que tenemos que admitir solicitudes de tamaño variable (ya que la cantidad de segmentos en la llamada de API puede variar enormemente, por la naturaleza de los datos de los documentos), tenía sentido procesarlas asincrónicamente y utilizar el servicio de vigilancia.
Otras mejoras
¡Podemos aumentar aún más el rendimiento de nuestra traducción automática! Estas son algunas ideas que estamos considerando para la próxima fase:
- Encontrar una manera de decirle a Kubernetes qué trabajadores suspender cuando se reduce la cantidad de réplicas. Por ejemplo, al elegir la cantidad de trabajadores que no están procesando activamente una solicitud, o los que tienen la caché modelo más pequeña. Actualmente no parece haber una forma de hacer esto (ver https://github.com/kubernetes/kubernetes/issues/45509).
- Dividir los documentos grandes en varias partes y procesar las partes en paralelo con múltiples trabajadores.
- Generar resultados parciales durante el procesamiento, así los clientes no tienen que esperar hasta que esté terminado todo el documento.
- Cuando se distribuye una solicitud a los trabajadores, tener una manera de priorizar la distribución a un trabajador que ya haya descargado y cargado previamente los modelos y los materiales necesarios para procesar el par de idiomas en la solicitud. Esto puede reducir el tiempo que demora procesar las solicitudes.