
Puede que ya sepas cómo las máquinas traducen entre dos idiomas humanos; si no es así, echa un vistazo a nuestra publicación de blog introductoria sobre el tema. Lo siguiente es una exploración avanzada en un aspecto de la traducción automática: transferencia de formato.
La traducción profesional es más compleja que solo traducir el texto bruto. La traducción debe preservar el formato, como la negrita, la cursiva y el marcado en la mejor medida posible.
En este artículo, describimos cómo Lilt conserva el formato en traducción. Cubriremos:
- Representación de etiquetas
- Alineación y atención de la palabra
- Visualización de las funciones
- Tolerancia a las faltas y múltiples extensiones de la palabra
Representación de etiquetas
Al localizar un documento a otro idioma, un traductor no solo debe traducir el texto, sino que también debe transferir el formato. Considere el siguiente fragmento de Wikipedia:

Primer párrafo del artículo de Wikipedia sobre traducción
Después de traducir el contenido de texto en bruto en, por ejemplo, alemán, el traductor aún tiene que transferir el formato (negrita, itálica, y marcado HTML) al texto alemán objetivo. El formato puede representarse como etiquetas de apertura y cierre que abarcan una determinada gama de caracteres en las etiquetas. Así es como se ve esto en la interfaz de Lilt:
Al principio, el traductor ve el segmento en el idioma de origen, lo que incluye las etiquetas de formato. El traductor traduce el segmento al interactuar con sugerencias generadas por la máquina. Después de terminar la traducción, Lilt transfiere automáticamente las etiquetas de formato a la versión del traductor. Idealmente, las etiquetas aparecen en posiciones razonables en la traducción; de lo contrario, el traductor puede cambiar manualmente las posiciones de las etiquetas a través de atajos de teclado o al arrastrar y soltar con el ratón.
Alineación y atención de la palabra
Recordatorio: los segmentos de origen en la traducción automática se dividen internamente en tokens, que son segmentos de sub-palabras.
Para transferir el formato tenemos que determinar las posiciones de las etiquetas de formato en la traducción. Para ello es útil saber qué palabras de la oración de origen y la traducción se corresponden entre sí - un problema llamado alineación de las palabras. Más tarde podemos utilizar esta información para determinar las posiciones de las etiquetas de formato en la traducción. Las redes
neurales para la traducción automática ya contienen un componente llamado "atención" que modela las correspondencias entre los tokens de la oración de origen y la traducción. La atención especifica cuánto influye cada token de la oración original en la generación de un token de la traducción como una distribución de probabilidades. La
atención se visualiza mejor utilizando una matriz con sombreado para indicar importancia. Aquí hay un ejemplo de una traducción de alemán a inglés, con los tokens en alemán a la izquierda y los de la traducción de inglés en la parte superior:
Esta es la matriz de atención promedio extraída de un sistema de TA basado en transformadores. Cuanto más oscuro es un lugar en esta matriz, más importante es el token en producir un determinado token en la traducción; es decir: mayor será la atención. Por ejemplo, los tokens más importantes en la generación del inglés “_believe” son, en alemán, “_glauben”, “_nicht” y “__”.
Podemos usar esta característica para transferir el formato también. Por ejemplo, si la palabra "glauben" estuviera en negrita en el texto original, podríamos usar la matriz de atención y seleccionar el lugar más oscuro de la fila, y marcar en negrita el token correspondiente en la traducción. Así tendríamos la palabra en inglés “believe” en negrita. Ahora a repetir para todos los tokens - ¿problema resuelto?
¡En absoluto! Desafortunadamente, la matriz de atención de arriba es bastante ruidosa. Mucha atención recae en el token de puntuación “_.”, que no refleja la importancia que un traductor humano daría al punto para producir las palabras individuales de la oración en inglés.
La arquitectura de Transformer que utilizamos para generar traducciones puede dividirse en un codificador y un decodificador. El codificador codifica la oración de origen en un vector por token de origen. El decodificador genera en iteración un token de la traducción. En cada paso el decodificador utiliza su propio estado - otro vector - para atender a los tokens de codificación más relevantes, combina el resultado con su propio estado y finalmente decodifica el siguiente token de la traducción (la publicación de blog original de Google contiene una visualización de este proceso).
Pero a veces hasta es posible generar la siguiente palabra de la traducción sin mirar la oración de origen. Para dar un ejemplo, ¿puedes adivinar cómo termina la siguiente oración? "El puente de Golden Gate está en San ..."
Incluso en estas situaciones, queremos forzar la red neuronal a atender a las representaciones de origen más relevantes. Así que diseñamos una capa de alineación dedicada para forzar la red neuronal a predecir el siguiente token, basado solo en una combinación lineal de la representación de origen. Usamos el estado del decodificador para calcular la matriz de atención que se utiliza para determinar los pesos para la combinación lineal. Aquí está la capa de alineación en el contexto del modelo de transformador completo:
En lugar de producir el siguiente token basado en el estado del decodificador como la línea de puntos a la derecha indicaría, la capa de alineación utiliza principalmente los estados del codificador para predecir el siguiente token. Esto obliga a la atención de la capa de alineación a centrarse en el token de origen más importante. La matriz de atención resultante ahora se ve como esta:
¡Nos hemos librado con éxito de altos valores de atención a la marca de puntuación en la traducción! Los puntos de atención restantes son ahora mucho más oscuros, con menos cajas "ligeramente grises" en todas partes. Efectivamente, hemos afilado la atención del modelo, que eventualmente conduce a una mejor proyección de etiquetas y por lo tanto una mejor transferencia de formato.
Visualización de funciones
Si bien la capa de alineación produce una atención razonable que podemos utilizar para transferir el formato, podemos mejorar. Para ello, daremos un paso atrás y recordaremos cómo las redes neuronales realizan el reconocimiento de imágenes.
Las redes neuronales para el reconocimiento de imágenes están entrenadas para predecir una etiqueta, por ejemplo la etiqueta "perro", para una imagen dada. En un modelo de reconocimiento de imágenes entrenado, uno puede analizar la característica que representa una neurona específica al generar una imagen de entrada de tal manera que esa neurona se active con fuerza.
Esta imagen generada activa una neurona que parece ser importante para reconocer a los perros:
Imagen optimizada para maximizar la salida de una neurona en un modelo de reconocimiento de imágenes. Fuente: distill.pub/2017/feature-visualization/
La imagen de arriba se crea empezando con una imagen de entrada al azar y optimizándola a través de la bajada de degradado con una función objetiva para activar una sola neurona en la red.
De vuelta a nuestro modelo de traducción: piensa en la matriz de atención anteriormente mencionada como una imagen de escala de grises. Recuerda que cada token de salida de la red de traducción corresponde a una neurona individual en la capa de salida de la red neuronal. Dado que conocemos la traducción a la que eventualmente transferiremos etiquetas de formato, podemos optimizar la imagen de atención hacia una alta activación de las neuronas de salida correspondientes a la traducción deseada.
En el video a continuación empezamos con la matriz de atención original y la optimizamos para una alta activación de las neuronas de salida deseadas utilizando unos pocos pasos de descenso de degradado:
Este proceso también conduce a una matriz de atención que es más útil para el formato de la transferencia.
Tolerancia a las faltas y múltiples extensiones de palabra
Hasta ahora, solo hemos considerado cómo transferir un par de etiquetas alrededor de una sola palabra. ¿Cómo manejaríamos varias palabras? Explicaremos un ejemplo más complejo y presentaremos un algoritmo para transferir formato que puede emparejar las inconsistencias en la matriz de atención generada.
Considere un par de etiquetas que abarque varias palabras como en la siguiente traducción de inglés a alemán:
Para averiguar cómo transferir las etiquetas de formato a la traducción, generamos una matriz de atención como de costumbre, pero solo consideramos el valor de atención más alto para cada token objetivo:
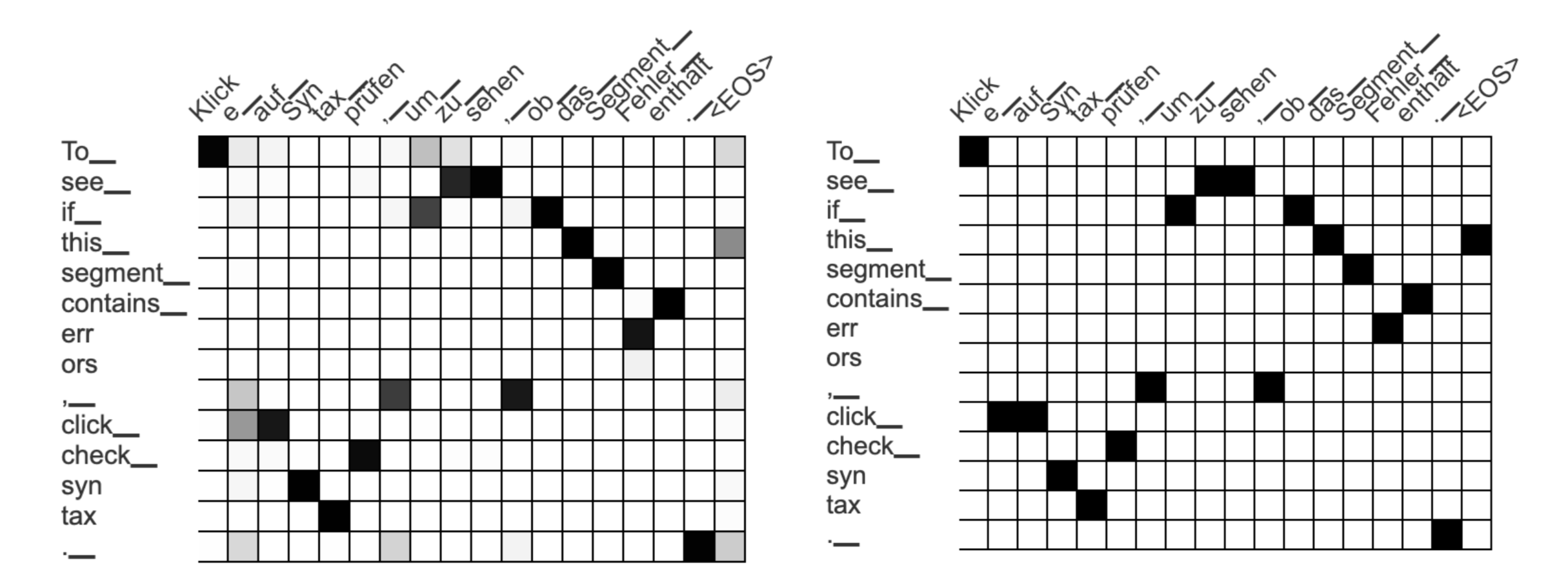
Matrices de atención generados automáticamente. La matriz izquierda contiene una distribución de probabilidad para cada token de salida alemán, la derecha solo conserva la puntuación de atención más alta para cada token alemán.
Una manera sencilla de transferir un par de etiquetas que cubra una frase de origen a una frase objetivo es la siguiente:
- Echa un vistazo a todos los valores de atención más altos de la frase de origen a los tokens objetivo
- Escoge el token objetivo a la izquierda y en la punta derecha en este conjunto
- Abarca el par de etiquetas alrededor de los tokens objetivo a la izquierda y en la punta derecha
En este ejemplo analizamos todas las puntuaciones de atención para la frase “To_ see_ if_ this_ segment_ contain_ err ors”, que son: “Klick”, “um_”, “zu_”, “sehen”, “ob_”, …, “Fehler_”, “enthält”. Seleccionamos la mayoría de estos tokens ("Klick" y "enthält") y dejamos que el par de etiquetas abarque todos los tokens en el medio:
Este podría ser un enfoque razonable si la matriz de atención nunca contenía ningún error. Pero la matriz de atención se genera automáticamente ¡y a menudo está mal! En nuestro ejemplo, la entrada incorrecta entre los tokens "To_" y "Klick" conduce a un lapso demasiado largo para nuestro par de etiquetas.
En Lilt desarrollamos un algoritmo que es más tolerante a las faltas. En lugar de seleccionar la palabra objetivo a la izquierda y la punta derecha como el límite para el lapso del par de etiquetas, definimos una puntuación para cada lapso posible en la traducción. Esta puntuación se calcula al resumir los siguientes cuentos:
- Número de entradas de atención de los tokens de origen cubiertos por el par de etiquetas a los tokens en el lapso de destino (puntuación en la plataforma)
- Cantidad de entradas de atención de los tokens no cubiertos por el par de etiquetas a los tokens fuerdelel lapso de destino (puntuación fuera de la plataforma)
Calculamos esta puntuación para cada lapso posible en la traducción y seleccionamos el lapso de mejor puntuación para transferir el par de etiquetas. Este enfoque asigna una puntuación baja al lapso objetivo demasiado largo del ejemplo anterior, porque la "puntuación fuera de la plataforma" es baja. El lapso de puntuación más alto para nuestro ejemplo es ahora “um zu sehen, ob das Segment Fehler enthält” con una puntuación de 15:
Arriba, el lapso de origen fijo se resalta en rojo y el lapso en la traducción para la que calculamos la puntuación se resalta en el amarillo. Para la puntuación a nivel de extensión contamos todos los cuadrados negros en la zona verde, que representa la atención entre los dos espacios. Para la puntuación fuera del lapso contamos los cuadrados negros en las dos áreas azules que corresponden a la atención que no está asociada con la fuente ni el lapso objetivo. Por lo tanto, obtenemos la puntuación de 8 (en la puntuación de la plataforma) + 7 (fuera de la puntuación de la plataforma) = 15.
El algoritmo de transferencia de marcado encontró este lapso óptimo al calcular la puntuación de todos los posibles lapsos objetivo. Esto conduce a los siguientes resultados más razonables a pesar de tener una matriz de atención imperfecta:
Lectura adicional
Esta publicación de blog describe la transferencia de formato, pero también destaca cómo las técnicas de una gama de diferentes áreas pueden mejorar el sistema de producción de Lilt para ayudar mejor a los traductores humanos. Si quieres profundizar más en los detalles técnicos de nuestros sistemas, lee algunas de nuestras investigaciones:
- Añadir la atención interpretable a los modelos de traducción neuronales mejora la alineación de las palabras: https://arxiv.org/abs/1901.11359
- La alineación de la palabra neuronal de extremo a extremo supera a Giza++: https://aclanthology.org/2020.acl-main.146/
- Transferencia de marcado Bilingüe automática: https://aclanthology.org/2021.findings-emnlp.299/