Written by Kelly Messori The idea that robots are taking over human jobs is by no means a new one. Over the last century, the automation of tasks has done everything from making a farmer’s job easier with tractors to replacing the need for cashiers with self-serve kiosks. More recently, as machines are getting smarter, discussion has shifted to the topic of robots taking over more skilled positions, namely that of a translator. A simple search on the question-and-answer site Quora reveals dozens of inquiries on this very issue. While a recent survey shows that AI experts predict that robots will take over the task of translating languages by 2024. Everyone wants to know if they’ll be replaced by a machine and more importantly, when will that happen?
Abstract: We compare human translation performance in Lilt to SDL Trados, a widely used computer-aided translation tool. Lilt generates suggestions via an adaptive machine translation system, whereas SDL Trados relies primarily on translation memory. Five in-house English–French translators worked with each tool for an hour. Client data for two genres was translated. For user interface data, subjects in Lilt translated 21.9% faster. The top throughput in Lilt was 39.5% higher than the top rate in Trados. This subject also achieved the highest throughput in the experiment: 1,367 source words per hour. For a hotel chain data set, subjects in Lilt were 13.6% faster on average. Final translation quality is comparable in the two tools.
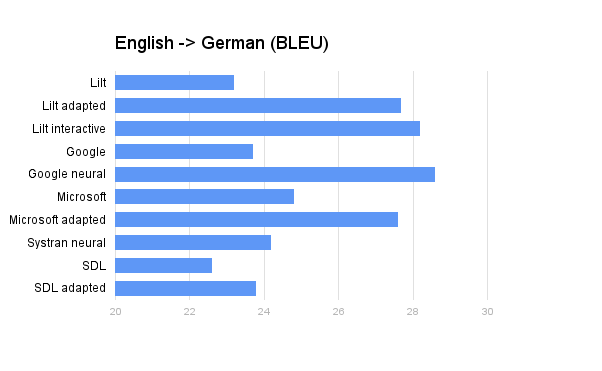
The language services industry offers an intimidating array of machine translation options. To help you separate the truly innovative from the middle-dwellers, your pals here at Lilt set out to provide reproducible and unbiased evaluations of these options using public data sets and a rigorous methodology. This evaluation is intended to assess machine translation not only in terms of baseline translation quality, but also regarding the quality of domain adapted systems where available. Domain adaptation and neural networks are the two most exciting recent developments in commercially available machine translation. We evaluate the relative impact of both of these technologies for the following commercial systems:
Guest post by Jost Zetzsche, originally published in Issue 16–12–268 of The Tool Box Journal. Some of you know that I’ve been very interested in morphology. No, let me put that differently: I’ve been very frustrated that the translation environment tools we use don’t offer morphology. There are some exceptions — such as SmartCat, Star Transit, Across, and OmegaT — that offer some morphology support. But all of them are limited to a small number of languages, and any effort to expand these would require painful and manual coding. Other tools, such as memoQ, have decided that they’re better off with fuzzy recognition than specific morphological language rules, but that clearly is not the best possible answer either. So, what is the problem? And what is morphology in translation environment tools about in the first place?


.jpeg)